October 25, 2022
R&D Cost Capitalization, also commonly known as Software Cost Capitalization, is seen as “necessary evil” for engineering leaders despite the pain the process often entails. For those less familiar with the concept, it’s when finance reports some amount of engineering work as a capital asset that amortizes over time, instead of being incurred as an operating expense in a single fiscal reporting period. Generally, capitalizing software development helps improve the financial profile of a company. It’s an invaluable accounting practice and perfectly legal.
There is nothing inherently “evil” about using well-established accounting practices to achieve certain financial objectives; the “evil” lies in the difficulty and amount of time required of your engineering team to gather this data properly. It’s incredibly difficult to categorize and organize your team’s work allocation without the proper tools and processes. Few engineering leaders can outright refuse to help with something so valuable to the business, but most leaders are reluctant to divert resources away from software development. Therein lies the conundrum…
Historically there have been two common approaches to gathering the data needed by your finance team for R&D Cost Capitalization. In this post, we’ll break down both methods, discuss why both of today’s approaches fall short, and why the third underutilized option involving Engineering Management Platforms is the least painful and most accurate approach.
Method #1: Manually logging and tracking hours
This method is exactly as it sounds, and it’s painful for everyone involved. We’d wager that there isn’t a single team member in any software organization anywhere that wants their leadership team asking them to log all the hours of their day. This type of management oversight can lead to frustration and ultimately morale issues. It goes against the culture of many software development teams that prioritize the mental health of the team, continuous improvement and delivery, and trust amongst the collective group.
There is a longstanding myth that logging hours spent on certain work is more accurate. While we understand how leaders might believe this to be true, more often than not, teams often feel inclined (or even indirectly incentivized) to overestimate work deemed as strategic or underestimate the work perceived to be less so. Not all work can fit nicely into designated categories of work as a part of this process. When this occurs, employees sometimes round up their time on tasks to get to the benchmark of 40 hours a week. For example, an employee may regularly add value to the team by reviewing another team member’s pull requests. We’d all agree this is a very important and helpful step in the software development process, but this type of work, depending on whether the reviewed code relates to a future capital asset, may not be “capitalizable” in the eyes of this accounting practice.
At the end of the day, manual time tracking can compromise team performance and/or morale in pursuit of higher company valuations. This approach is bad for culture and leads to inaccuracies, among other negative side-effects.
Method #2: Estimating work allocation
This second approach approaches the problem from the opposite side of the spectrum from self-reported tracking. Instead leaders attempt to estimate work allocation with the [lack of] tools currently available to them. Some leaders will examine how teams and roles are structured and scoped, and then estimate the total percentage for certain types of work (as projects/epics) based on their role. This usually requires finding a proxy unit of measure for total work hours or work and then trying to “translate” that unit of measure into total time or percentage of work. Some common units of measure include the number of tickets a person worked on, the total number of story points, or completed issues.
While this does not introduce the administrative and team burden of the first approach, this method also falls short for multiple reasons. Jellyfish research found in 2021 that leaders were overestimating their team’s work in certain areas by as much as 41%. The reason for this is that traditionally technical leaders lack the tools and processes necessary to quantify how much time our software teams spend on various work categories.
Even if your inherent ability to estimate work allocation is higher than that of your peers, the units of measure, such as story points, were never intended to be used for estimating engineering time or work completed. There are way too many variables at play (just consider how differently your teams might assign story point values) that will drastically skew your final results. The same concept applies to other units of measurement such as # of tickets, completed issues, etc. Unfortunately there is no way (without making significant non-data driven assumptions) to standardize these units of measure across all your teams and then directly convert them to time or total work allocation percentage. Because there has not been a better way, teams put in a ton of work into chasing a flawed final result.
Method #3: Engineering Management Platforms
The third option, outputting data from an Engineering Management Platform (EMP), is a more accurate approach that also solves for the culture hurdles of manual time tracking. To illustrate this point, we’ll need to discuss how EMPs gather required data for this exercise, and how the process behind the work allocation modeling allows for the highest accuracy possible.
EMPs capture workflow information and metadata (e.g. pull requests, code commits) from tools that engineers use on a day-to-day basis (e.g., Jira, Github) to identify what engineers are spending their time on. An EMP should not track hours, but rather uses these activities to passively identify and quantify engineering work.
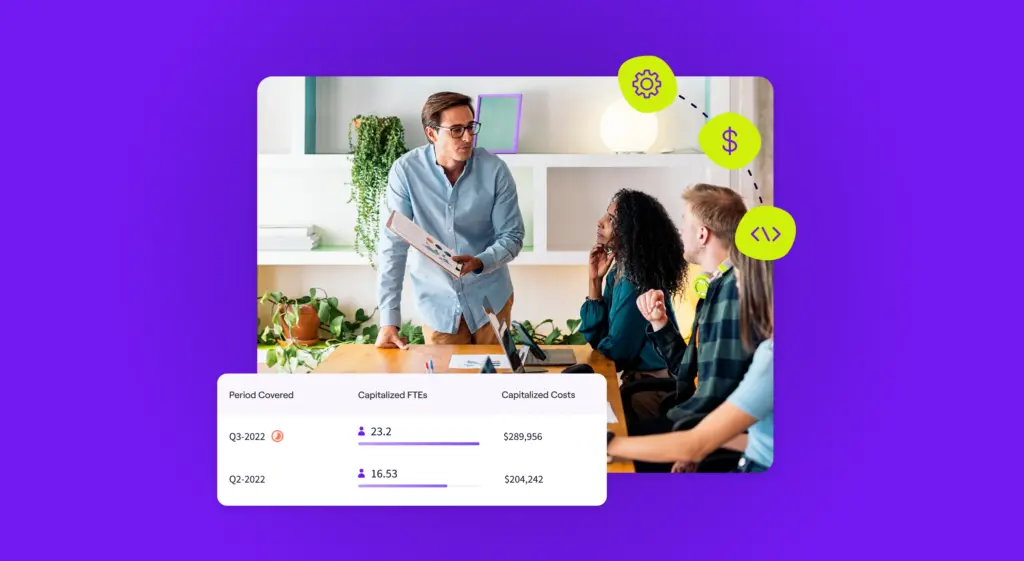
Advanced EMPs can then “allocate” the observed work across the various engineering projects, deliverables, and/or activities. “Allocation” of work is done so in the unit of “Full-Time Equivalents” (FTE), where 1 FTE represents 100% of a person-equivalent’s engineering effort.
This granular and contextualized capture of engineering efforts allows for automated, accurate reporting of capitalizable time without the administrative burdens or inaccuracies of the other approaches outlined. Customizable standard reports also improve collaboration between Engineering and Finance teams, while improving response to future audits.
The Future of R&D Cost Capitalization
We believe EMPs will be a new way forward for companies leveraging R&D Cost Capitalization. We hope EMPs help make R&D Cost Capitalization data gathering so easy to do, that it overcomes its stigma of being a“necessary evil,” and becomes a “no-brainer” task for the companies that choose to leverage this helpful accounting practice.
Jellyfish recently launched its cost capitalization product, designed to automate and improve the accuracy of tracking and reporting required for capitalizing R&D efforts. To learn more about cost reporting with Jellyfish DevFinOps visit our solution page or request a demo today.