In this article
Here at Jellyfish we recently teamed up with OpenAI to study how AI coding tools are affecting developer productivity. We found that adoption of AI tools correlated with significant increases in productivity, particularly PR throughput. In fact, achieving full adoption of AI coding tools (i.e. every engineer using AI every time they code) corresponded to a 2.1x change in PRs merged.
However, we all know that software engineering teams are complex entities, each with their own unique constraints, strengths, and challenges. Perhaps you’re seeing exciting gains… or perhaps you’re finding the impact of your AI investments underwhelming. In either case, there are many factors beyond adoption that affect PR throughput. Let’s talk about the most important: your code architecture.
What Do We Mean By “Code Architecture”?
What Do We Mean By “Code Architecture”?
By code architecture, we mean the strategy by which your products and services are organized and coordinated across your source code repositories. Think monorepo vs. polyrepo, monolith vs. microservices, or a centralized vs. federated product/platform strategy.
One simple metric for understanding your code architecture is weekly active repositories: how many distinct repositories did you merge code into this week? However, this metric grows linearly with the number of engineers – larger companies tend to have more repositories, representing more products and services as they scale. Alternatively, here at Jellyfish we’ve developed a new metric: weekly active repositories per engineer. This metric is more useful in practice, characterizing your organization’s repo strategy independent of scale. A low number of active repos per engineer indicates a more consolidated architecture (monorepos, monolithic services, and/or centralized products) while a high number indicates a more distributed architecture (polyrepos, microservices, and/or federated products).
To understand different code architectures and how they affect AI productivity gains, we investigated data from 321 Jellyfish customers from January to August 2025, representing more than 3.8 million pull requests across 130,000 code repositories.
The chart below shows the distribution of weekly active repos per engineer over the data set (9,602 total “company-weeks”, i.e. snapshots of each company for the various weeks over the observation period).
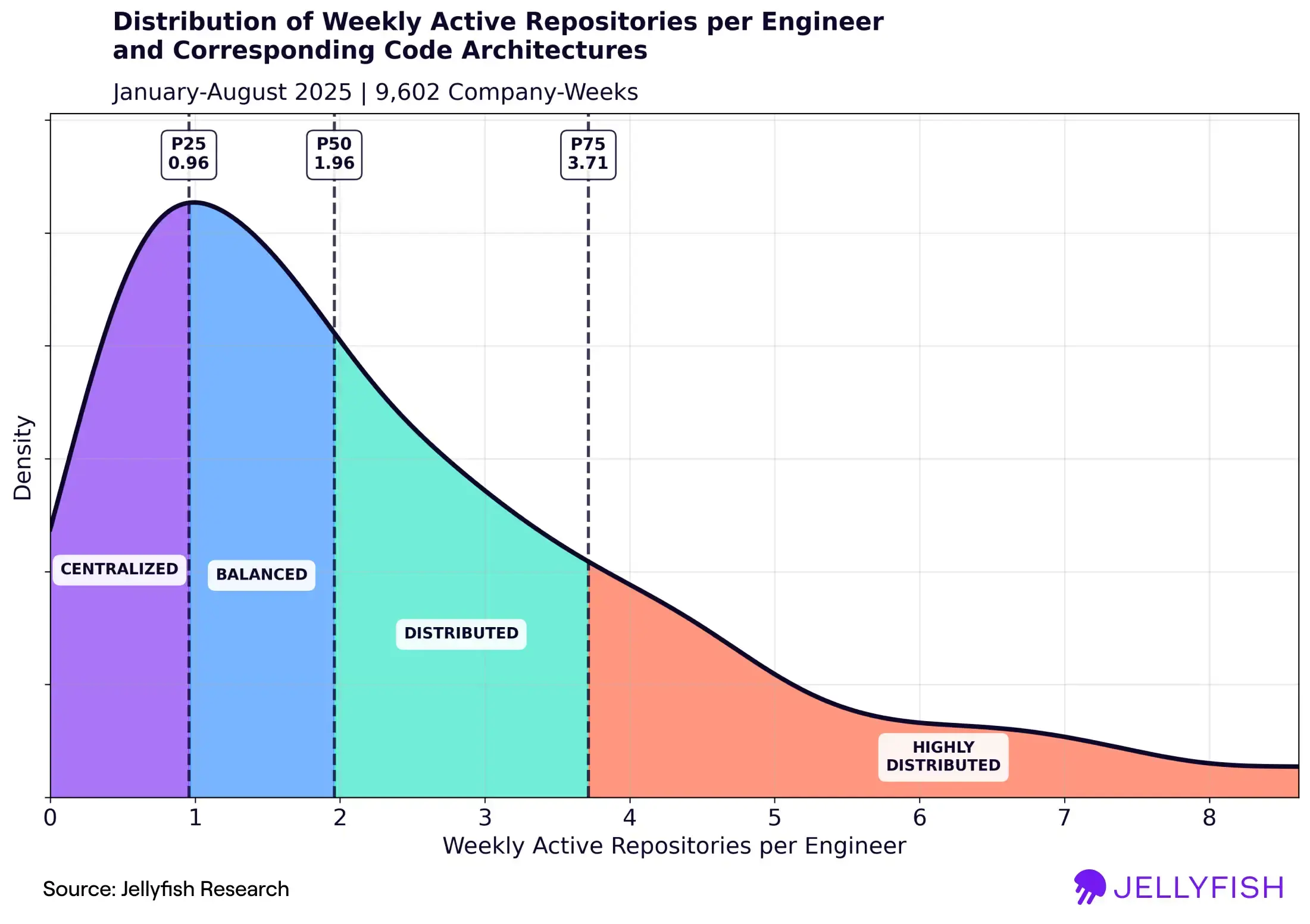
This chart illustrates the wide range of distinct code architectures that companies adopt. We’ve broken the distribution down into quartiles, labeling each with the code architecture that most characterizes it. The table below summarizes the different regimes and the types of architecture strategies that give rise to each.
| Quartile | Code Architecture | Weekly Average Repos per Engineer | Description |
| 1 | Centralized | < 1 | Monorepos, monolithic services, small number of products |
| 2 | Balanced | 1–2 | Moderate distribution of code, services, and products |
| 3 | Distributed | 2–3.7 | Polyrepos, distributed services, large number of products |
| 4 | Highly Distributed | 3.7+ | Extensive microservices, highly federated products |
How Code Architecture Affects AI Impact
How Code Architecture Affects AI Impact
As in previous analyses, we specify a company-wide AI adoption rate that measures how regularly engineers in an organization are using AI coding tools. It is defined as the fraction of active coding days an engineer used AI, averaged across all engineers on the team.
When we segment the data by code architecture, we find that coding behaviors and the effects of AI adoption vary widely across the cohorts. The chart below contains four scatter plots, where each data point is a snapshot of a single company and week, indicating the PRs merged per engineer and AI adoption rate for that company-week. Each scatter plot corresponds to a different code architecture (quartile) – centralized, balanced, distributed, and highly distributed. We also fit trend lines to measure the relationship between change in AI adoption rate and changes in PR throughput.
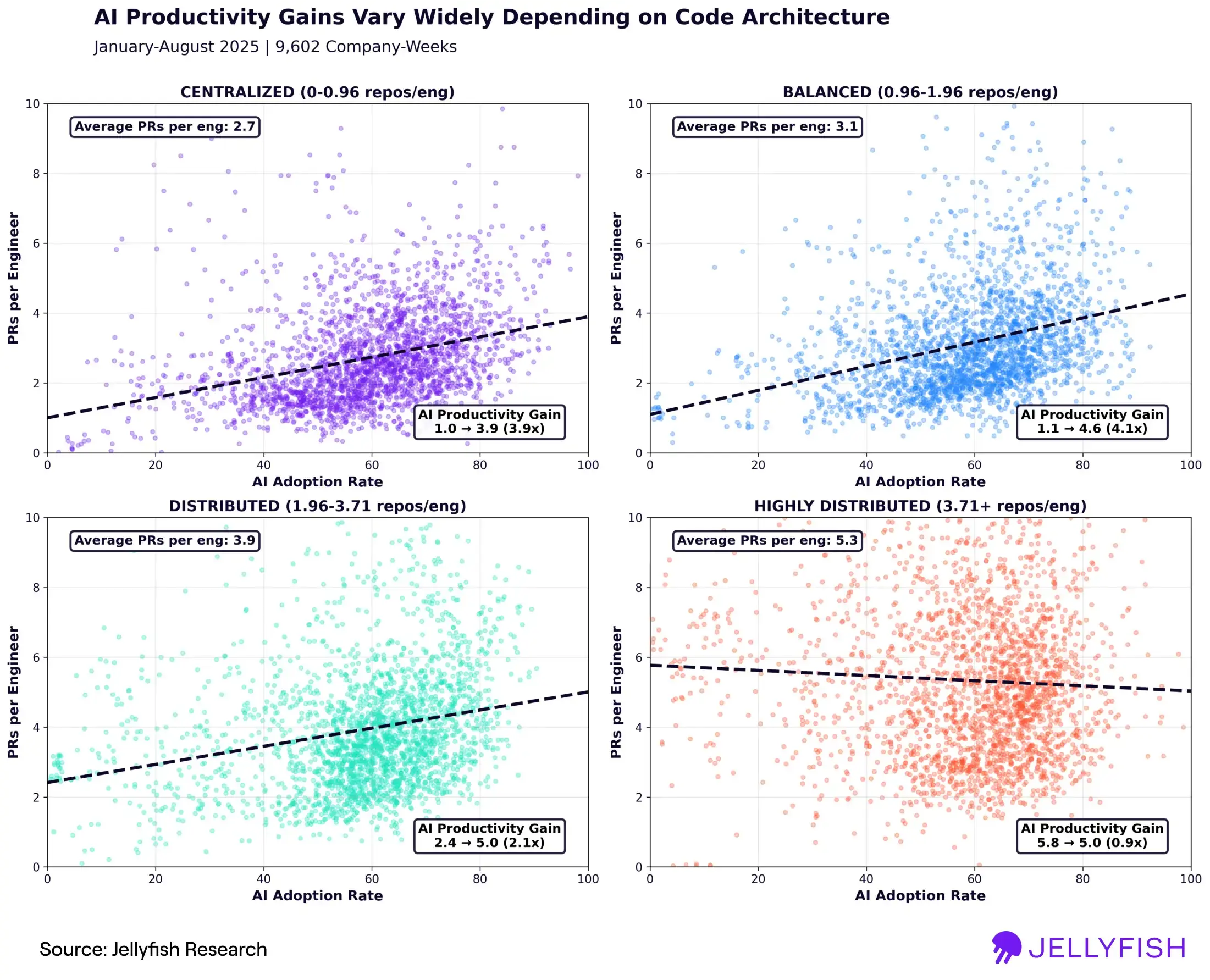
The first thing to notice is that the average volume of PRs varies across the code architectures, increasing as code becomes less centralized. Independent of AI coding practices, teams with highly distributed architectures merge approximately 2x the PRs per engineer compared to those with centralized architectures (5.3 vs. 2.7 PRs per engineer on average).
Note that this difference does not suggest a disparity in overall productivity. Rather, the higher PR volume associated with more distributed architectures is primarily due to the higher level of cross-repo coordination required. In a distributed architecture, shipping a single feature typically requires changes across many services, and a single upgrade or code migration may have to be duplicated across multiple repositories, resulting in a higher number of pull requests on average.
Most interestingly, the correlation between AI adoption and PR throughput also varies across code architectures. Teams with centralized and balanced architectures can expect a ~4x change in PRs per engineer (approximately double what we observed in our previous study) when going from 0% to 100% adoption of AI coding tools. Teams with distributed architectures can expect a ~2x change – about half of what we observe for centralized and balanced architectures.
For the top quartile the relationship between AI adoption and throughput is the noisiest, and the correlation indicates a slight negative trend, indicating that adoption of AI tools may actually be slowing down teams with highly distributed code architectures. We summarize all of the results in the table below.
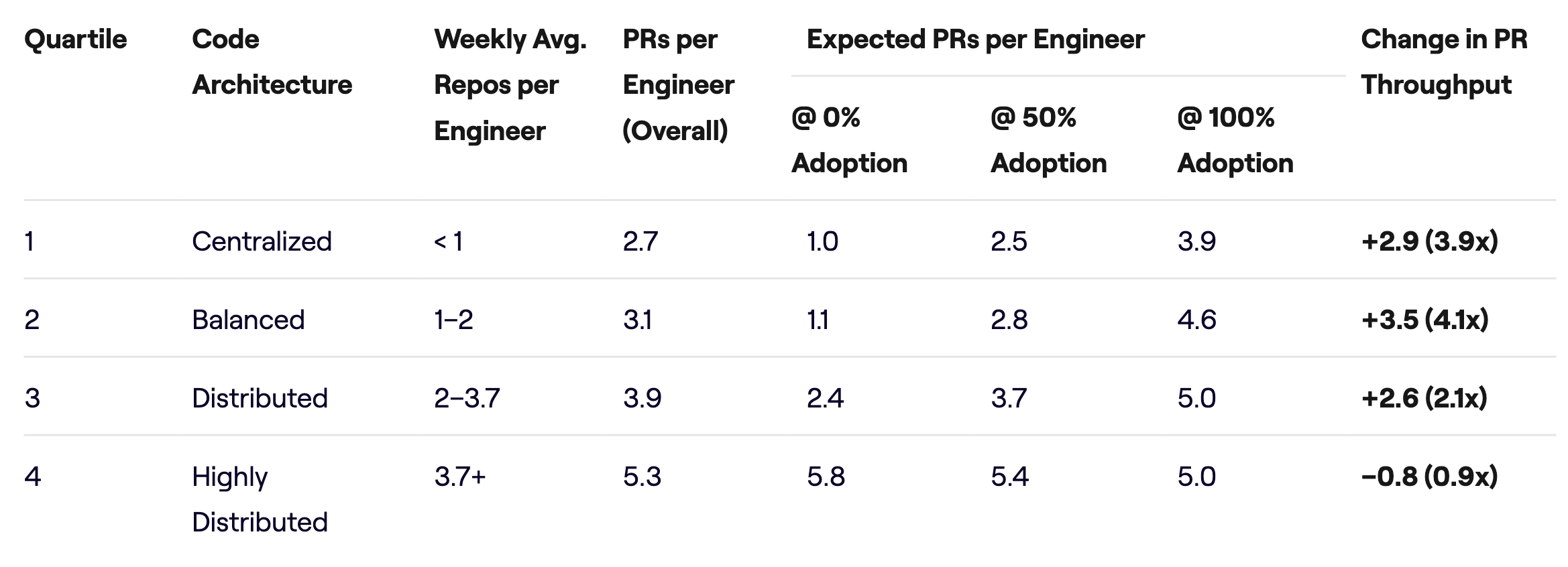
The obvious question is, what is causing these disparities? One explanation is the importance of context to the effectiveness of AI coding tools. In the past year we have seen huge advances in the abilities of LLMs to perform indexing and search as well as tool use, and in many ways today’s AI tools are limited only by the quality of the context provided to them. This may be why code architecture matters: the more centralized the code, the easier it is for AI coding tools to find the context they need to complete work accurately, effectively, and with all relevant changes included. By contrast, highly distributed systems likely rely on human experts who understand the architecture and can manage the complex cross-repo coordination required to push code effectively.
Does this mean that organizations with highly distributed architectures are doomed? Not at all: context engineering and AI agents are evolving fast, and these organizations may have a lot to gain through better automation of coding work that spans repositories, services, and products, especially if it is highly redundant and can be easily validated. Coding, testing, and review agents that can coordinate work across repositories could yield huge gains for these kinds of architectures.
For now though, the data is clear: your code architecture is a critical (and perhaps unexpected) factor in the return on your AI investments. As you scale your use of these powerful new tools, take a hard look at your code architecture – a more consolidated codebase may be the key to unlocking the promise of bigger AI productivity gains.
About the author

Nicholas Arcolano, Ph.D. is Head of Research at Jellyfish where he leads Jellyfish Research, a multidisciplinary department that focuses on new product concepts, advanced ML and AI algorithms, and analytics and data science support across the company.