In this article
Every time you pull a developer into an urgent bug fix, they have to drop the complex feature work they were in the middle of.
They’ll need to re-read code, retrace logic flows, and remember architectural decisions before they can write another line.
This is the tax of context switching. To see how bad it gets, just take a look at what developers are saying online:

(Source)
This isn’t an isolated feeling, either. Research shows that a single, unplanned context switch can consume up to 20% of a developer’s cognitive capacity.
And that 20% loss isn’t a one-off. It happens with every Slack ping, every unexpected meeting, and every “quick question” from a junior colleague. Now, multiply that cost by the number of interruptions per day across your entire team.
It’s a costly problem, but it’s also a solvable one. Below, we’ll look at what’s causing all this chaos and how to fix it for good.
What Is Context Switching?
What Is Context Switching?
Context switching in software engineering is when developers have to stop what they’re working on, shift their attention to another task, and then later try to resume the original project.
This means dropping your current mental model of the code structure, problem context, and planned approach. Then, you have to rebuild a completely different one for the new task.
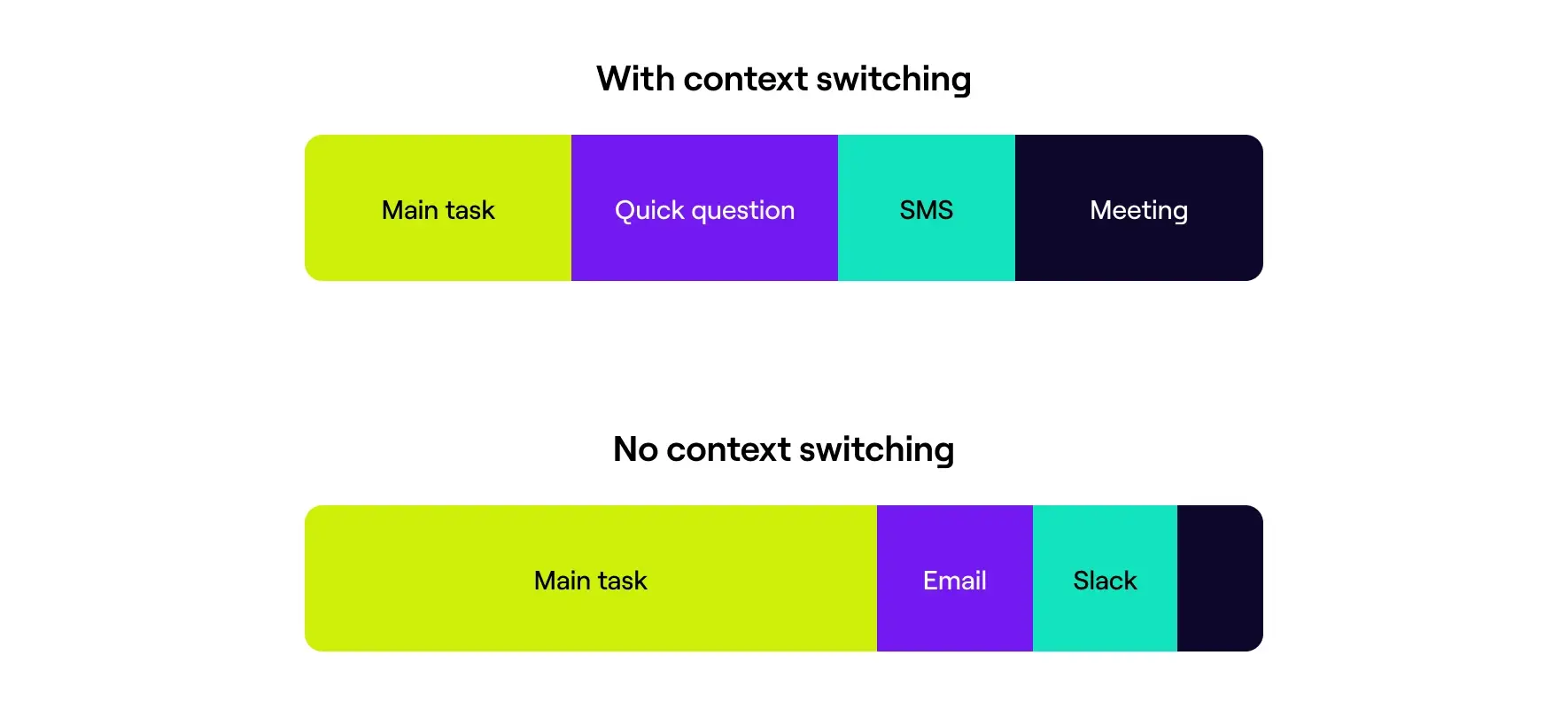
This isn’t the same as multitasking. Multitasking is having Spotify on while you code – parallel activities that use different parts of your brain.
Context switching forces you to completely abandon one complex mental model and build another. You can’t keep both active.
Engineering teams get hit harder than most professions because development demands interconnected mental models. Even when you work on a single feature, you track database schemas, API contracts, business logic, and user workflows all at once.
Sophie Leroy’s research on “attention residue” explains why rebuilding context takes so long. When you switch between different tasks, part of your brain stays stuck on the original task.
You can’t fully focus on the new task because you’re still processing the old one. For developers who work with complex code abstractions, this mental residue hangs around for 30-60 minutes.
Common triggers include Slack messages, meeting interruptions, code review requests, and production alerts. But not all switches hurt equally:
- Low-cost switching happens between similar contexts. Reviewing a PR for code you wrote yesterday or switching between related features in the same codebase costs maybe 5-10 minutes. You’re using the same mental models, just applying them differently.
- High-cost switching happens when engineers must completely change problem domains. For example, jumping from frontend styling to database optimization to infrastructure troubleshooting. Most developers need 30-60 minutes to get back to their previous productivity level after switches like these.
The Impact of Context Switching on Developers
The Impact of Context Switching on Developers
Context switching creates a cascade of problems that engineering leaders often don’t see coming.
Here’s specifically how it impacts your development team’s performance and output:
Decreased Productivity and Time Loss
Context switching costs developers far more than the actual minutes spent in meetings or handling interruptions. Research by Dr. Gloria Mark shows that it takes an average of 23 minutes and 15 seconds to fully regain focus after an interruption.

For developers, this means a single “quick question” from a colleague can destroy nearly half an hour of productive coding time. And most of this lost time comes from the cognitive rebuilding that happens after the interruption.
Reduced Code Quality and Increased Errors
Context switching can also devastate code quality. In fact, research shows that interrupted tasks take twice as long and contain twice as many errors as uninterrupted tasks.
When developers jump between multiple contexts, they miss edge cases, write incomplete tests, and introduce subtle bugs that only come up later.
For example, a developer who switches between debugging a database query and setting up a user interface feature might forget to handle null values properly or miss validation logic. This then creates technical debt that compounds over time.
Increased Developer Stress and Burnout
The psychological toll of constant context switching creates a vicious cycle of mounting pressure, and eventually, burnout.
The UCI Irvine study also found that developers who faced frequent interruptions reported higher levels of stress, mental fatigue, and time pressure. Each context switch drains a bit more mental energy until developers feel completely exhausted by day’s end.
The stress compounds over time. When developers spend every day rebuilding mental models and fighting for flow state time, they start dreading work entirely.
Common Causes of Context Switching in Software Development
Common Causes of Context Switching in Software Development
Most context switching comes from a few predictable sources that engineering teams deal with every day. The main culprits usually include:
Communication and Collaboration Patterns
The always-on culture means notifications, questions, and updates arrive all day long, which forces developers to drop their current work repeatedly.
The frustration this creates is real and widespread among developers. Here’s how this Reddit developer explained their experience:

(Source)
These are some of the common patterns that hurt developer focus:
- Instant messaging creates an expectation of immediate responses, even for non-urgent questions
- Open offices invite drive-by interruptions and casual “quick questions” throughout the day
- Daily standups that run long and dive into implementation frameworks instead of quick status updates
- @mentions in multiple Slack channels that demand attention across different contexts
- Video calls scheduled without clear agendas that could have been async discussions
- “Can you hop on a quick call?” messages that turn into hour-long debugging sessions
Inefficient Process and Workflow Issues
When workflows prioritize process over productivity, developers spend more time managing systems than writing code. And what should be simple tasks stretch into multi-day ordeals.
This developer’s Reddit post explains perfectly how process overhead kills momentum:

(Source)
Common workflow issues that force context switches:
- Waiting for code reviews that take days, while you start other tasks to stay busy
- Multiple approval layers for simple changes, where you have to chase down different stakeholders
- Slow CI/CD pipelines that force developers to switch tasks during 30-minute build times
- Separate ticketing systems for bugs, features, and ops work
- Manual deployment processes that need coordination across multiple teams
- Flaky test suites that fail randomly and demand immediate investigation
- Environment setup issues that block progress and force pivots to other work
Suboptimal DevOps Practices
Broken DevOps practices force developers to become part-time ops engineers, where they switch between coding and firefighting throughout the day.
This means that developers are handling tasks that specialized teams used to take care of, which can quickly become overwhelming.
This Reddit comment explains how DevOps has (d)evolved in many organizations:

(Source)
DevOps failures that fragment developer focus include:
- Production alerts that page the entire team instead of following proper escalation paths
- Developers pulled into infrastructure issues because “you touched it last.”
- No clear ownership between dev and ops responsibilities (leads to constant handoffs)
- Lack of proper monitoring that turns every issue into an all-hands debugging session
- Manual deployment steps where developers have to babysit releases
Tool Sprawl
When you need different apps for coding, testing, deployment, and monitoring, every tool switch slowly kills your flow and forces you to rebuild your mental context.
This Reddit developer nails what’s happening with today’s bloated tech stacks:

(Source)
Some common tool fragmentation issues that break developer focus include:
- Switching between the IDE, terminal, browser, and database clients for a single feature
- Multiple CI/CD systems are running in parallel because migrations never finish
- Separate tools for logging, monitoring, and alerting that need cross-referencing
- Documentation scattered across Confluence, Notion, Google Docs, and README files
- Version control is split between GitHub, GitLab, and legacy SVN repositories
5 Strategies and Best Practices to Reduce Context Switching
5 Strategies and Best Practices to Reduce Context Switching
Context switching might feel inevitable, but it’s actually quite manageable with the right approach.
These five best practices will give your developers the sustained focus they need to do their best work:
1. Force-Rank Priorities and Limit Work-in-Progress (WIP)
Start by force-ranking your work. Not everything can be priority #1. Pick the most important task, finish it, then move to the next.
This sounds obvious, but most teams fail here because they’re afraid to say no to stakeholders. When leadership asks for status on five different features, they need to hear “We’re focusing on X first, then Y. The others wait.”
Set WIP limits that your team can follow:
- Define maximum limits for active tickets per developer (typically 1-2 items max)
- Block new work assignments when they reach current limits
- Automate alerts when pull requests sit too long (24 hours to reviewers, 48 hours to leads and authors)
- Ask developers to check review queues before picking up new tickets
This Reddit developer shared their team’s approach:

(Source)
This approach creates natural pressure to complete work, so you don’t accumulate half-done tasks.
PRO TIP 💡: Use Jellyfish’s resource allocation dashboard to see exactly how your developers’ time and cognitive load splits across projects. When you can visualize that Mary is juggling 4 different features while Mike has 1, it becomes obvious why her work takes longer to complete.
2. Harden Systems to Reduce Firefighting
Nothing destroys focus like production fires. When your systems are fragile, every deployment becomes a potential emergency that pulls developers away from planned work.
The knee-jerk reaction is usually to set up more monitoring, more alerts, and more processes around incident response. But that just creates more interruptions.
Start with the basics that prevent fires:
- Track your production issues – if you’re dealing with more than 2-3 per week, pause feature work and fix the underlying problem
- Write tests that catch bugs before they hit production (unit tests for logic, integration tests for connections, end-to-end tests for critical paths)
- Build in safety nets so when one thing breaks, everything else doesn’t go down with it
- Document exactly how to fix common problems (include the actual commands and database queries so nobody has to figure it out from scratch at 2 AM)
- Make sure every service has one team that owns it, so there are no more “I thought you were handling that” conversations during outages
But before you rush to set up another process, make sure you actually do have a process problem and not a leadership one. This Reddit developer explains the difference:

(Source)
If your systems break because of rushed timelines and messy instructions, adding another review step won’t help. Fix the root cause first.
3. Automate and Improve Tools to Minimize Wait Times
When developers sit idle while tests run, builds compile, or deployments crawl along, they naturally switch to other tasks and lose mental context.
What you should do is outline these friction points and either automate them completely or make them fast enough that developers can stay focused on their current work.
But don’t just throw tools at problems without thinking them through. This engineering leader on Reddit explains why:

(Source)
Focus on automation that tackles common wait times:
- Speed up your CI/CD pipeline so builds and tests finish in under 10 minutes
- Set up hot reloading for local development to see changes instantly
- Automate code formatting and linting to eliminate back-and-forth during reviews
- Use one-click deployment scripts that don’t need manual steps
- Create development databases that reset quickly between test runs
You can keep developers in flow if you remove the small delays that tempt them to check email or start other tasks.
PRO TIP 💡: Jellyfish’s cycle time metrics reveal exactly where your pipeline is slow. You’ll see data showing “reviews sit for 3.2 days on average” so you know what to fix first.
4. Centralize and Improve Team Documentation
When information is scattered across wikis, chat histories, and people’s heads, every new task becomes a research project. It only creates unnecessary dependencies on specific team members.
The key is to treat your documentation like any other important feature. This team lead on Reddit shared their approach that worked:

(Source)
Many modern teams adopt this “docs-as-code” philosophy that treats documentation with the same rigor as application code. This means writing docs in the same repositories as your source code, using version control, and updating documentation as part of your regular development workflow.
Even Google’s Riona MacNamara explains how this philosophy has completely changed the way Google approaches documentation.
You can start with these high-impact areas:
- Architecture decisions and system relationships
- Setup instructions that work on fresh machines
- Common debugging procedures and troubleshooting steps
- API contracts and integration patterns
Keep documentation close to the code. Developers won’t maintain docs that are in separate systems they rarely visit. Tools like Sphinx, GitBook, or even well-organized README files work better than enterprise wikis that gather dust.
The upfront investment pays off when new team members can onboard without constant interruptions and experienced devs can work independently across different parts of the system.
5. Define Clear Communication Protocols
Without clear rules about when and how to communicate, teams default to interrupting whoever seems available.
You need explicit rules about what demands someone’s immediate attention versus what can wait, and where different types of questions should go.
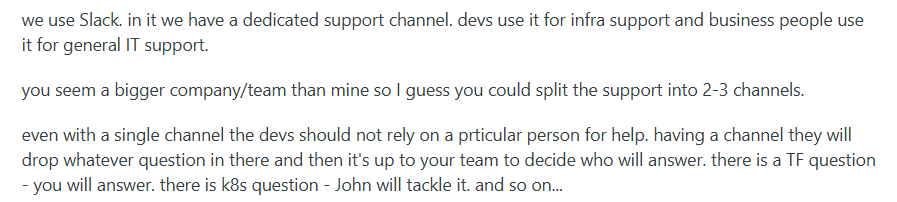
Here’s how this team solved it with simple channel organization:
(Source)
Create dedicated channels for different types of requests instead of direct messages or random @mentions. This distributes the load and lets the right person respond when they’re available.
You can also set clear expectations about response times and urgency levels:
- Immediate response needed → Production issues, blockers that stop work completely
- Same-day response → Code review requests, clarifying instructions for current work
- Next-day response → General questions, non-urgent help, planning discussions
- Async only → Status updates, FYI messages, documentation requests
It’s always a good idea to set up “focus time” blocks where developers can work without interruptions.
For example, many teams use morning hours (9-11 AM) as interruption-free time when possible. And make it clear that non-urgent questions should wait until after focus blocks end.
PRO TIP 💡: Print this out and stick it next to every developer’s monitor. When someone approaches with a “quick question,” they can glance at the card and immediately know whether to interrupt or find another way to get their answer.
| Urgency level | When to use | Response time | Method |
| 🚨 Interrupt now | Production down, security breach, major blocker | Immediate | Direct message, phone, tap shoulder |
| ⚡ Same day | Code reviews, current sprint blockers, deployment approvals | Within 8 hours | Slack mention in channel |
| 📅 Next day | General questions, non-urgent bugs, future features | Within 24 hours | Slack channel, email, ticket |
| 📝 Async only | Status updates, docs, FYI messages, suggestions | No deadline | Email, shared docs |
Making an Invisible Problem Visible: How Jellyfish Reduces Context Switching
Making an Invisible Problem Visible: How Jellyfish Reduces Context Switching
Context switching problems are often invisible to engineering leaders until they become serious productivity drains.
You can sense that your team is struggling, but you can’t pinpoint exactly where time gets lost or why certain projects consistently run behind schedule.
Jellyfish is a software engineering intelligence platform that shows you exactly how your teams spend their time and what’s pulling them away from focused work.
It connects with your existing tools (Jira, GitHub, Slack, and more) to automatically track where developers lose focus, which meetings eat up their coding time, and how interruptions affect project delivery.
Here’s a specific breakdown of what you can do with Jellyfish:
Reduce Multitasking and Optimize Resource Allocation Across Projects
Jellyfish’s resource allocation shows you exactly where every hour goes across roadmap features, bug fixes, infrastructure work, and those random support requests that always seem to pop up.
The platform pulls data from all your engineering tools automatically with zero manual tracking on your part.
You can compare effort across teams, benchmark against similar organizations, and see how work breaks down by individual contributors.
Most importantly, you’ll spot the red flags:
- Developers bouncing between too many projects
- Teams spread thin across competing priorities
- Key initiatives getting starved of resources
The platform even helps you calculate allocations automatically using the “Work Model” tool, so you get accurate insights without disrupting engineer workflows.
Stay Ahead of Deadlines to Minimize Disruptions
When teams miss deadlines, it disrupts everyone’s work. Your best people have to abandon their current tasks to handle the crisis. Jellyfish’s delivery management features help you spot problems before they escalate.
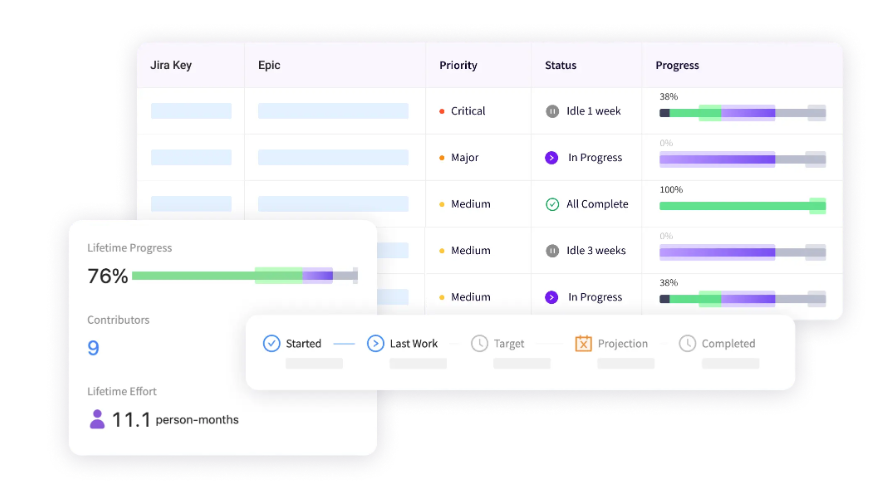
The platform tracks project progress and provides realistic timelines based on actual data. You get early warning signals when projects drift off track, so you can tackle issues proactively.
And when developers hit their deadlines consistently, you avoid the cost of context switching that come from constant firefighting.
Spot Process Gaps That Disrupt Development Flow
Delays in your development process force teams to context switch while they wait for blockers to resolve. But with the Jellyfish Life Cycle Explorer, you can see exactly which stages consistently create these time-sinks.

The platform shows you how long tasks sit in each stage (refinement, development, review, and deployment) so you can see what’s slowing developers down and making them jump between tasks.
You can drill into specific issues to understand why certain work stalls, then use these insights to improve your planning and prevent future delays.
Use Engineering Metrics to Spot Focus Problems Early
Jellyfish gives you engineering metrics that show the real problems in your development process. You can track cycle times, change lead times, and deployment frequency to see where work gets stuck and forces teams to multitask.
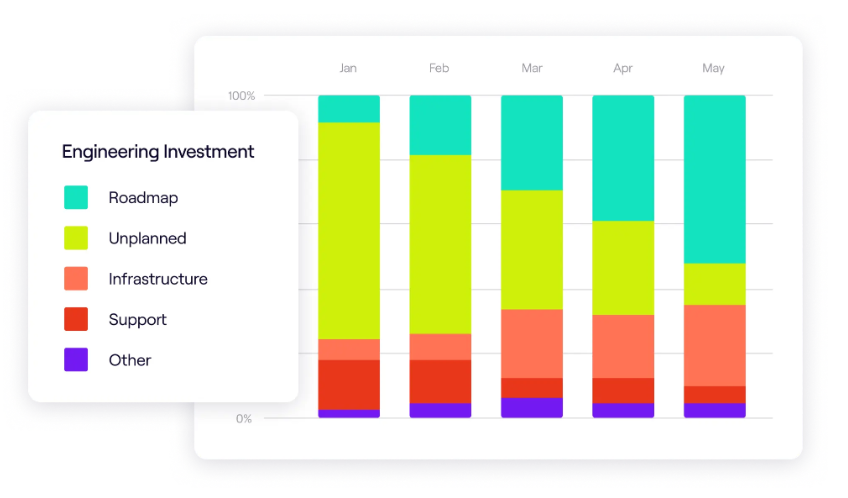
The platform provides you with DORA metrics and lets you customize your own DevOps measurements to build an elite-performing team.
When you can see patterns in your data, you can fix process issues before they force your teams into reactive, context-heavy work patterns.
Analyze Meeting Overhead to Protect Development Focus
Jellyfish Meeting Insights integrates with your Google Calendar to show you exactly how much time your teams spend in meetings versus actual development work.
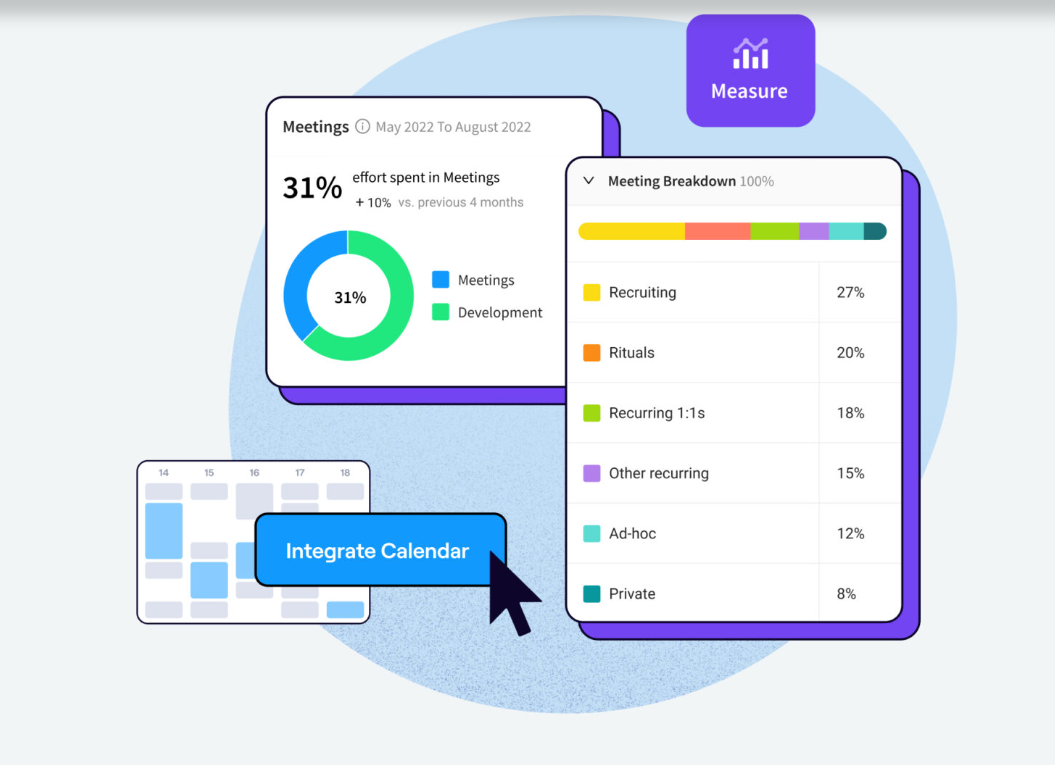
The platform categorizes different types of meetings, including 1-on-1s, recruiting sessions, sprint ceremonies, and general collaboration. You can see which activities consume the most engineering capacity.
With this data, you can create actual coding time, cut unnecessary meetings, or set up mornings where developers can focus without interruption.
Context switching might be invisible to executives, but it’s costing your engineering team their sanity.
Book a Jellyfish demo and see exactly how much focus time your team is losing every day.
FAQs
FAQs
Isn’t some context switching just part of a senior developer’s job?
Absolutely — senior developers need to mentor teammates, review code, and help with architecture decisions.
The key is to tell the difference between valuable context switches and pointless interruptions that only break concentration.
For example, a senior developer who chooses to pause their work to help a junior teammate with a blocker makes sense. But getting pinged every 20 minutes with “quick questions” that could wait until the next standup destroys developer productivity.
How do I get buy-in from a team that is used to multitasking?
It’s a good idea to first measure the current state without changing anything. Most developers don’t realize how often they’re switching contexts until they see the data.
Track interruptions for a week, then show the team how much time they’re losing to recovery. Once people see that their “quick Slack check” is costing them 25 minutes of focus time, they become natural advocates for protecting deep work.
How do these practices apply to a small startup where everyone wears multiple hats?
You have to be strategic about when people switch hats. Instead of developers jumping between coding, customer support, and sales calls throughout the day, create dedicated time blocks for each role.
Maybe mornings are for coding, afternoons for customer issues, and Fridays for cross-functional work. You’ll still wear multiple hats, but you’ll just wear one at a time instead of changing every few minutes.
How can I balance protecting my team’s focus while still being responsive to stakeholders?
Create predictable communication rhythms that work for both developers and stakeholders:
- Set clear expectations about response times for different types of requests
- Define “work hours” when developers are available for questions
- Use async communication by default, with synchronous meetings only for urgent decisions
- Designate specific team members to handle stakeholder communication on rotating schedules
- Provide regular updates through dashboards instead of constant check-ins
You want to make sure that stakeholders feel heard without turning every developer into a constantly-available help desk.
Most stakeholders are happy to work within reasonable boundaries once they understand the productivity impact of constant interruptions.
How do I actually measure if our efforts to reduce context switching are working?
Look for improvements in:
- Deployment frequency: Teams with better focus ship more consistently and with fewer last-minute scrambles.
- Code review turnaround time: Less context switching means faster, more thoughtful reviews without creating new issues.
- Bug rates in production: Fewer context switches lead to fewer rushed mistakes and better code quality.
- Time from code complete to deployment: Streamline workflows with less task jumping reduce the general cycle time.
- Developer retention and satisfaction: People stay longer and report higher job satisfaction when they can do deep work.
Learn More About Developer Productivity
Learn More About Developer Productivity
-
- What is Developer Productivity & How to Measure it the Right Way
- What is Developer Productivity Engineering (DPE)?
- 9 Common Pain Points That Kill Developer Productivity
- How to Improve Developer Productivity: 16 Actionable Tips for Engineering Leaders
- Automation in Software Development: The Engineering Leader’s Playbook
- 29 Best Developer Productivity Tools to Try Right Now
- 21 Developer Productivity Metrics Team Leaders Should Be Tracking
- AI for Developer Productivity: A Practical Implementation Guide
- How to Build a Developer Productivity Dashboard: Metrics, Examples & Best Practices
- Developer Burnout: Causes, Warning Signs, and Ways to Prevent It
- 10 Peer Code Review Best Practices That Turn Good Developers Into Great Ones
About the author

Lauren is Senior Product Marketing Director at Jellyfish where she works closely with the product team to bring software engineering intelligence solutions to market. Prior to Jellyfish, Lauren served as Director of Product Marketing at Pluralsight.