In this article
Platform engineering is a high-stakes investment. When done right, it accelerates time-to-market, reduces cognitive load, and empowers developers. When done wrong, it creates a ghost town —an expensive collection of tools and portals that no one uses.
Despite the clear benefits, many platform initiatives stall or fail. This isn’t usually due to a lack of technical skill or budget. It happens because organizations fall into systemic traps—anti-patterns—that unintentionally kill adoption and trust.
This guide identifies the most dangerous platform engineering anti-patterns so leaders can spot them early, course-correct, and build an internal developer platform that actually delivers value.
What is an Anti-Pattern?
What is an Anti-Pattern?
Before diving into specific examples, it’s helpful to define what we mean by an anti-pattern. It is not just a simple mistake; it is a structural failure that often looks like a good idea on the surface.
As Donella H. Meadows describes it in her seminal book, Thinking in Systems:
“An antipattern can be understood as a systemic trap or archetype. A recurring dysfunctional pattern in complex systems that leads to undesirable outcomes.”
In the context of platform engineering, the most common anti-patterns rarely arise from incompetence. No leader sets out to execute a strategy they know will fail. Instead, they emerge unintentionally as a consequence of the complex nature of technological transformation.
If you observe the symptoms outlined below, you have likely encountered one of these systemic traps. Recognizing them is the first step to escaping them.
Strategic Anti-Patterns
The most dangerous anti-patterns aren’t technical bugs; they are strategic missteps. These occur when leadership misunderstands the purpose of a platform, treating it as a rebranding exercise or a silver bullet rather than a product that must solve real problems.
1. Rebranding the Operations Team
This is perhaps the most common trap. Organizations realize they need platform engineering, so they simply rename their existing Infrastructure or Operations team to Platform Engineers without changing the underlying operating model. The team continues to work in a ticket-based, reactive mode, handling manual requests for environments and access.
Red flags to watch for:
- The platform team backlog is filled with support tickets, not product features.
- The development team still has to wait for a human to provision infrastructure.
- Success is measured by ticket resolution time rather than adoption or velocity.
A user on Reddit called out this specific dysfunction: “I’ve seen teams simply being renamed from operations or infrastructure teams to platform engineering teams, with very little change or benefit to the organization… centralized ‘DevOps’ teams aren’t an anti-pattern in itself. The only way you can scale properly is centralizing… but again, the name of these teams should really be named ‘Platform’ or ‘SRE’.”
How to break the pattern:
Shift from a service mindset to a product mindset. The platform team’s goal is to build self-service capabilities that eliminate the need for tickets. They should measure success by how few tickets they receive because developers can serve themselves.
Learn more → Here are 8 clear signs your organization needs platform engineering. (If you recognize most of them, you’ve probably outgrown your current infrastructure.)
2. The Field of Dreams Fallacy
“If you build it, they will come.” In platform engineering, this is almost never true. Many teams spend months (or years) building a massive, comprehensive IDP in isolation, only to launch it and find that no one wants to use it because it doesn’t solve the developers’ actual day-to-day problems.
Red flags to watch for:
- The platform team has little to no direct interaction with application developers during the build phase.
- The roadmap is driven by technical nice-to-haves rather than user pain points.
- Adoption is low, and developers actively find workarounds to avoid using the platform.
How to break the pattern:
Treat developers as customers. Conduct user research, build a Minimum Viable Platform (MVP) that solves one specific, high-friction problem (like deploying a hotfix), and iterate based on feedback.
Marketing your platform internally is just as important as building it.
💡Jellyfish insight: Build developer surveys from research-backed templates for instant insights into the health of your engineering organization, industry benchmarks, and more.
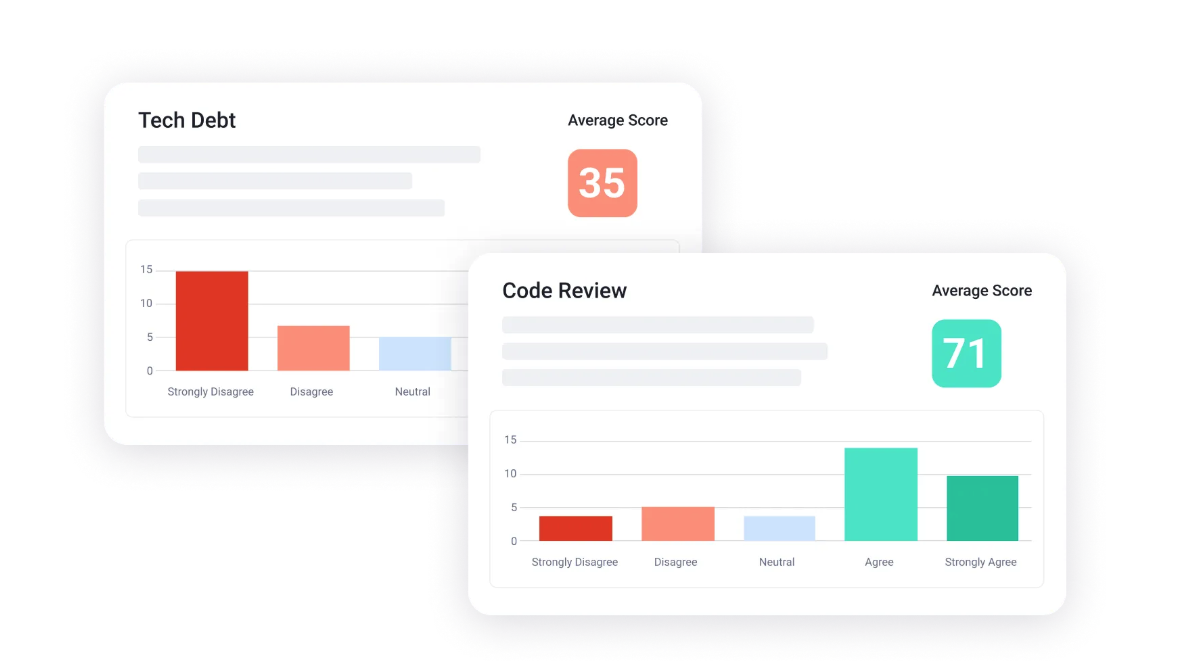
3. The Magpie Platform (The Shiny Object Syndrome)
This trap involves chasing the newest, shiniest technology—like a complex multi-cloud service mesh or the latest bleeding-edge tool—instead of solving boring, real production problems. The platform becomes a playground for the platform engineers, rather than a utility for the organization.
Red flags to watch for:
- The platform stack is overly complex, using new tools that few people understand.
- The team prioritizes “resume-driven development” over stability.
- Basic developer friction points (like slow tests or confusing docs) are ignored in favor of implementing cool new tech.
A Reddit user warned about this trap perfectly: “Adopting the new technology or tool rather than fixing pain points / improving your one. There will always be the hot new thing, that seems great until you actually start using it and find out all the caveats you didn’t consider.”
How to break the pattern:
Be boring. Focus relentlessly on existing production pain points. Prove value by solving the unglamorous problems first—like standardizing CI/CD reliability or simplifying secret management—before adopting complex new technologies.
Execution Anti-Patterns
Execution Anti-Patterns
Even with the right strategy, teams can fail during the build phase. These anti-patterns occur when the platform team focuses on the wrong technical deliverables or mismanages the scope of the platform.
4. Building the Front End First
A major misconception is confusing the developer portal with the platform itself. Teams often spend months configuring a beautiful instance of Backstage, cataloging services, and tweaking the UI, without building the underlying automation engine that actually does the work.
Red flags to watch for:
- The platform team is obsessed with the service catalog metadata, but hasn’t automated environment provisioning.
- Developers visit the portal to find a link, but then have to leave it to perform the task (e.g., deployment) manually.
- The portal is just a static directory, not a self-service
How to break the pattern:
Focus on the API, the golden paths, and the automation first. The UI is just an interface; the value is in the engine. A platform with a clunky CLI that automates a 3-hour task is infinitely more valuable than a beautiful portal that does nothing.
5. The Platform for Everything (Over-Engineering)
This is the trap of trying to abstract away every possible use case, creating a rigid, complex black box. The platform team aims to build a perfect abstraction layer on top of AWS or Kubernetes, so developers never have to touch the underlying infrastructure. This inevitably fails because it blocks power users and requires the platform team to maintain a massive surface area.
Red flags to watch for:
- The platform team becomes a bottleneck because they have to update a template every time a developer needs a new database setting.
- Developers complain that the platform is getting in the way of simple tasks.
- Adoption stalls because edge cases aren’t supported.
A user on Reddit highlighted the inevitability of this failure: “You can try all you like… to create a self-service platform based on custom templates… but at the end of the day, you will always run into limitations that a developer needs covered that your template doesn’t. And if you fight this, you will literally end up with a nightmare.”
How to break the pattern:
Build Thinnest Viable Platforms (TVPs). Solve the 80% use case (the common path) and allow for “paved roads” that are optional. Give developers escape hatches to access the raw infrastructure when the abstraction doesn’t fit their needs.
💡Jellyfish insight: Use Jellyfish to measure the investment of software development efforts, and make sure that engineering outputs at every level are aligned with the right business outcomes.
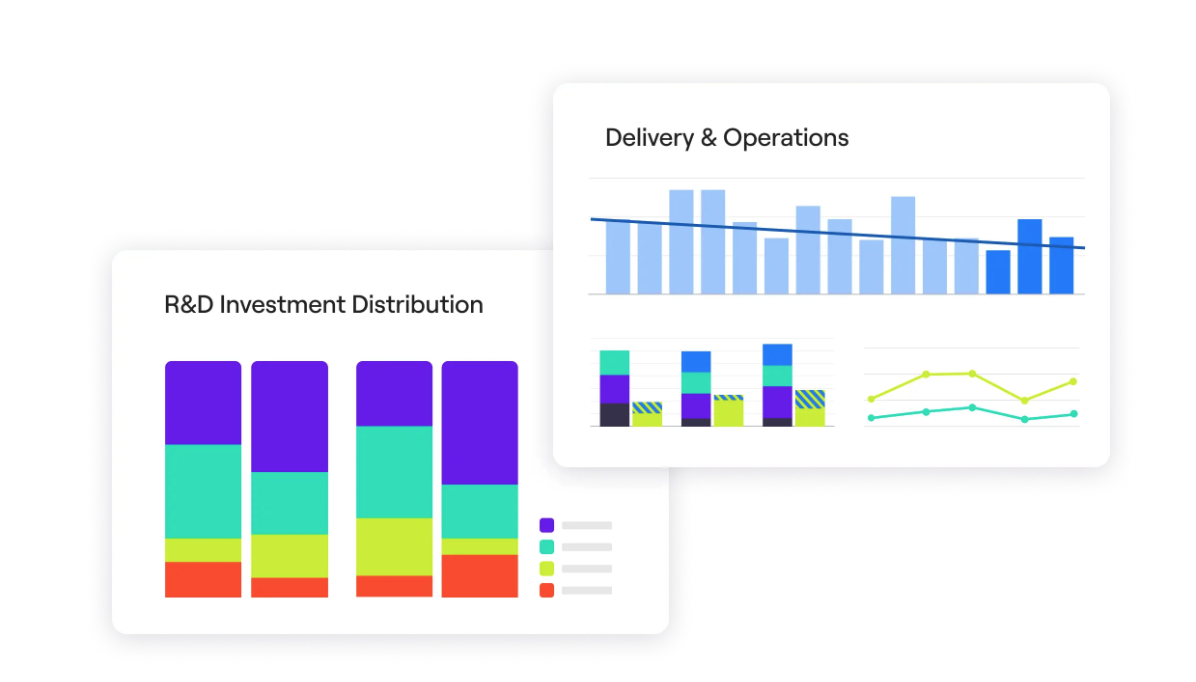
6. Neglecting the Day 2 Reality (Under-Investment)
Many organizations treat the platform as a project with a launch date. Once the MVP is shipped, the team is disbanded or moved to the next fire, leaving the platform to rot. In reality, a platform is a product that requires continuous maintenance, support, and iteration.
Red flags to watch for:
- The documentation is outdated and refers to tools that no longer exist.
- Bugs in the platform toolchain go unpatched for weeks.
- Developers have lost trust and are reverting to manual scripts.
A DevOps engineer described this 90% solution cycle perfectly: “Get it to about 90% done… ‘Right [now] it’s working fine, and we have a list of features to deliver, we’ll gold plate it later’ – time called, system has to go into use while incomplete… I’ve seen this happen so many times over my career, and it’s maddening.”
How to break the pattern:
Budget to run the platform, not just build it. Establish a permanent product team responsible for the platform’s lifecycle, SLA, and roadmap. If you can’t afford to maintain it, don’t build it.
💡Jellyfish Insight: Use resource allocation data to ensure you aren’t under-investing. If your platform team’s allocation to Maintenance or KTLO drops to near zero after launch, it’s a warning sign that technical debt is accumulating, and the platform is likely degrading.
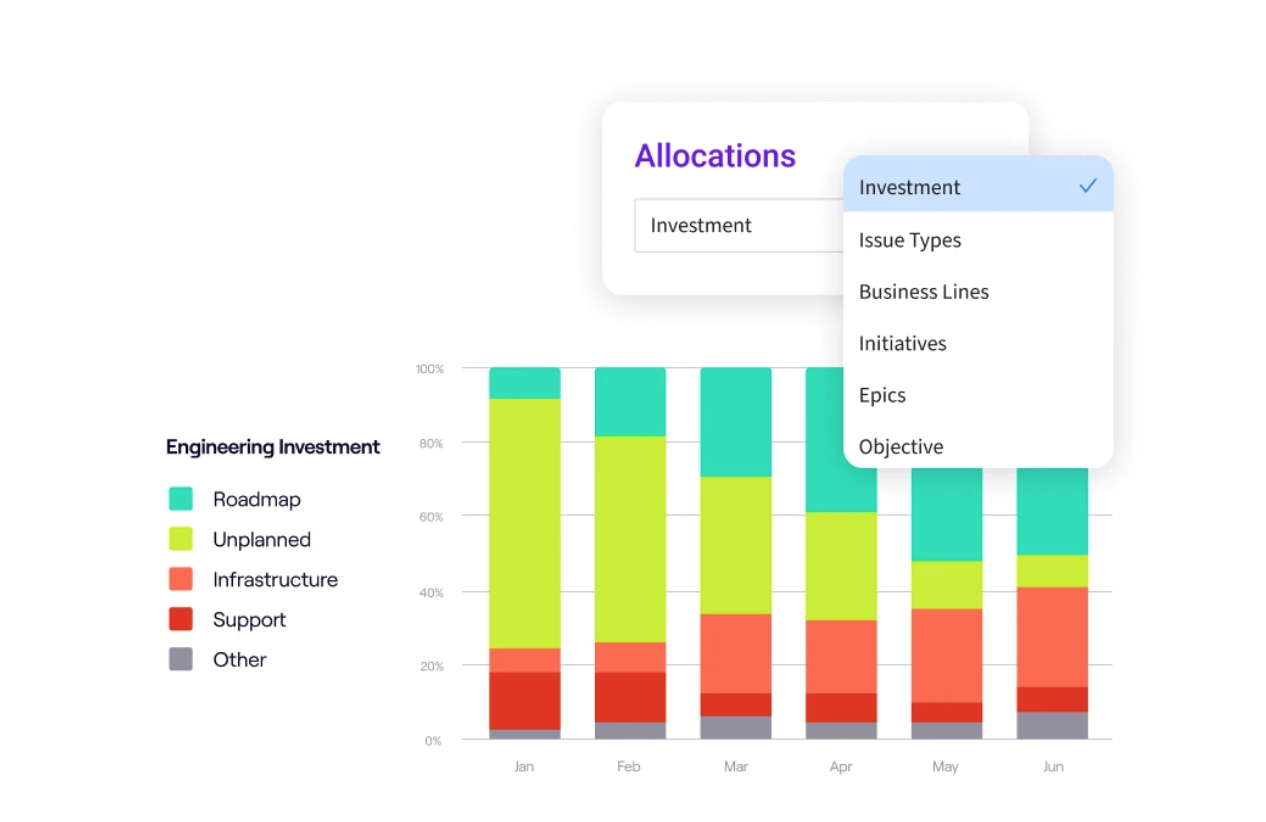
Management and Cultural Anti-Patterns
Management and Cultural Anti-Patterns
The final set of anti-patterns relates to how the platform is governed, staffed, and measured. A platform is only as good as the team that builds it and the management strategy that supports it.
7. The Skill Concentration Trap
This happens when an organization moves all its best senior engineers onto the platform team. While this seems logical to build a great product, it inadvertently “brain drains” the application teams. The product teams lose the expertise they need to understand what they are consuming, becoming helpless and dependent on the platform team for every minor issue.
Red flags to watch for:
- Application teams stop troubleshooting their own issues and immediately escalate to the platform team.
- The platform team becomes a bottleneck for basic architectural decisions.
- A “them vs. us” mentality develops between the elite platform team and the “feature factory” product teams.
How to break the pattern:
Focus on enablement and education, not just tooling. The platform team’s job is to mentor application teams and raise the overall engineering bar. Implement embedded rotations where platform engineers join product teams for a sprint to transfer knowledge and build empathy.
8. Mandated Adoption
This is the fastest way to kill a platform’s culture. Leadership decides that to ensure ROI, everyone must use the new platform. This removes the incentive for the platform team to build a compelling product and hides critical feedback loops because developers stop complaining and just suffer in silence (or build shadow IT).
Red flags to watch for:
- Adoption metrics are high (forced), but NPS or satisfaction scores are abysmal.
- Developers are building secret workarounds to bypass the standard tools.
- The platform team stops iterating on user experience because they have a captured audience.
How to break the pattern:
Make adoption voluntary. The platform must earn its users by being the path of least resistance—the easiest, fastest, and safest way to ship code. If teams aren’t using it, treat it as a bug in the product, not a compliance issue with the team.
9. Tracking the Wrong Metrics
Many platform teams struggle to prove their value because they measure the wrong things. They focus on vanity metrics like number of portal logins or number of API calls, which don’t reflect actual business value.
This leads to a disconnect where the platform team thinks they are succeeding, but leadership sees no improvement in velocity.
Red flags to watch for:
- Reporting focuses on activity (outputs) rather than outcomes.
- Leadership threatens to cut the platform budget because they don’t see the ROI.
- The team optimizes for metrics that don’t improve the developer experience.
How to break the pattern:
Measure business value. Shift your focus to metrics that matter to the business: time-to-market, reduced onboarding time, and cost savings from shared infrastructure. Connect your platform initiatives directly to these outcomes.
Align, Measure, and Prove Your Platform's Impact with Jellyfish
Align, Measure, and Prove Your Platform’s Impact with Jellyfish
Platform engineering anti-patterns thrive in the dark. When you lack visibility into how your platform is actually being perceived and used, it’s easy to fall into the Field of Dreams trap or fail to justify the budget needed to maintain it.
Jellyfish goes beyond basic activity tracking to provide the engineering management intelligence you need to steer your platform strategy and avoid these systemic failures.
- Measure sentiment, not just activity: Don’t assume high usage means success. Use DevEx surveys to capture qualitative feedback alongside quantitative data. Know how developers feel about your platform—whether it’s reducing cognitive load or adding to it—so you can iterate based on user reality, not just login counts.
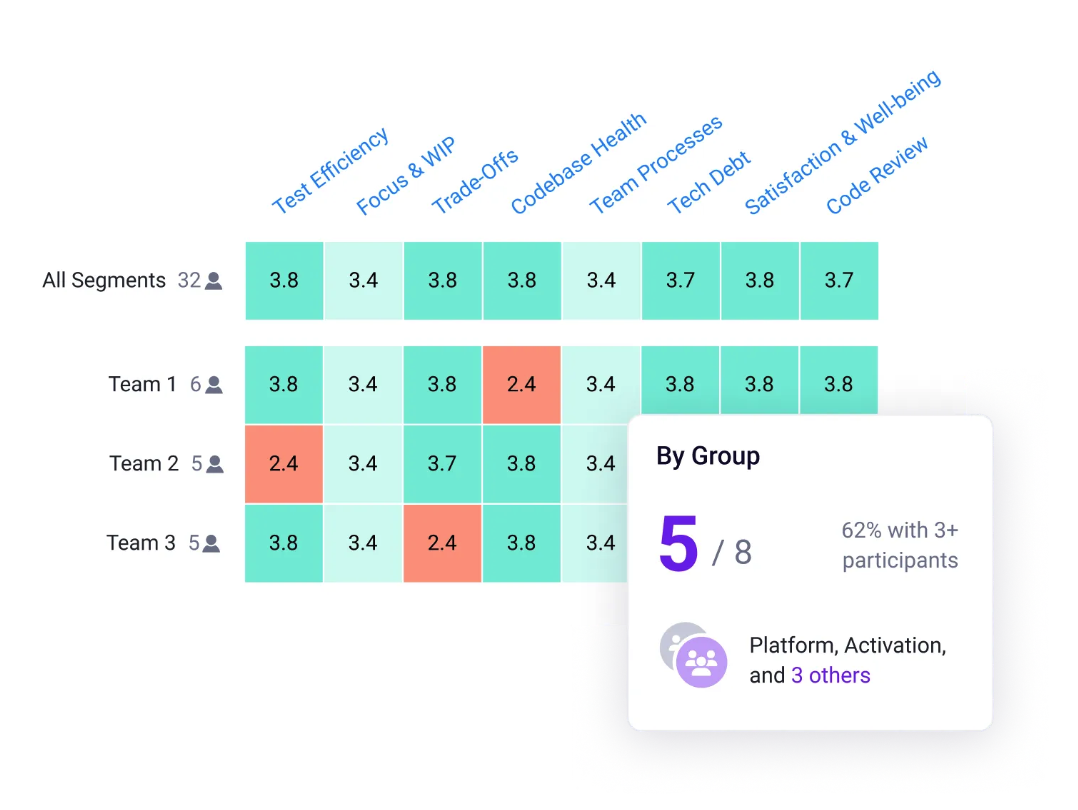
- Align platform work to business goals: Prevent your team from becoming a “rebranded ops” ticket factory. Jellyfish helps you visualize your platform team‘s work in the context of business priorities, ensuring they are focused on strategic capabilities that drive the business forward, rather than just keeping the lights on.
- Prove the financial value: Combat the under-investment trap by demonstrating the financial impact of your platform. With automated software capitalization modeling, you can accurately track the investment going into your platform assets, helping you justify the headcount and resources needed to treat your platform as a long-term product, not a temporary project.

Build a platform that lasts. To learn more about Jellyfish, book a demo now.
FAQs
FAQs
Why is treating your platform as a product considered the solution to many anti-patterns?
Treating your platform as a product shifts the focus from technology to user needs. It requires a dedicated product manager to define the roadmap based on feedback, ensuring the platform solves real problems for stakeholders. This approach prevents the Field of Dreams trap and ensures the platform evolves to streamline the development process rather than becoming a bottleneck.
How does the Magpie Platform anti-pattern affect software delivery?
Chasing shiny new tools creates a fragmented ecosystem that is hard to maintain. It slows down software delivery because teams are forced to learn complex, unstable technologies instead of shipping new features. A successful platform focuses on boring, reliable standards that make workflows predictable and scalable.
Can relying too much on open source tools be an anti-pattern?
Not inherently, but it becomes one if you lack the skills to support them. Adopting complex open-source projects without a plan for maintenance and integration can create silos where only one person understands how the backend works. This creates a “bus factor” risk for the entire software engineering organization.
How do we avoid the duplication-of-effort anti-pattern?
Duplication happens when teams don’t know what already exists. A centralized platform with a discoverable software catalog (often hosted on GitHub or similar tools) solves this. By providing modular, reusable components, you encourage teams to become contributors to the platform rather than building their own isolated solutions from scratch.
Learn More About Platform Engineering
Learn More About Platform Engineering
- The Complete Guide to Platform Engineering
- Platform as a Product: The Foundation for Successful Platform Engineering
- When to Adopt Platform Engineering: 8 Signs Your Team is Ready
- Platform Engineering vs. DevOps: What’s the Difference?
- How to Build a Platform Engineering Team: Key Roles, Structure, and Strategy
- Understanding The Platform Engineering Maturity Model
- How to Build Golden Paths Your Developers Will Actually Use
- Best 14 Platform Engineering Tools Heading Into 2026
- 8 Benefits of Platform Engineering for Software Development Teams
- 17 Platform Engineering Metrics to Measure Success and ROI
- The Top Platform Engineering Skills Every Engineering Leader Must Master
- 11 Platform Engineering Best Practices for Building a Scalable IDP
- What is an Internal Developer Platform (IDP)?
About the author

Lauren is Senior Product Marketing Director at Jellyfish where she works closely with the product team to bring software engineering intelligence solutions to market. Prior to Jellyfish, Lauren served as Director of Product Marketing at Pluralsight.




