In this article
Most code review processes are broken. Developers either rubber-stamp everything to avoid conflict or get stuck in endless debates about code style while real issues slip through.
You end up with the worst of both worlds — all the friction of a thorough review process with none of the quality benefits.
Things have gotten so bad that some developers are posting on forums about their companies abandoning code reviews entirely:

(Source)
And the teams that benefit from code reviews have cracked the code on three things:
- Building a culture where honest feedback flows without drama
- Structuring review mechanics that don’t waste time
- Measuring the right metrics to know if it’s working
Good code reviews spot bugs early, spread knowledge across the team, and keep code quality high without killing velocity. But you need a framework that manages all three areas systematically.
These ten practices below work together as a complete system. We’ll show you exactly what to do, step by step.
1. Create a Team Culture That Welcomes Code Feedback
1. Create a Team Culture That Welcomes Code Feedback
Code reviews should feel like debugging with a colleague who has your back. But too often, they become judgment sessions where developers feel they’re on trial.
Developers either pick apart spacing and variable names, but miss actual logic bugs, or they wave everything through just to avoid arguments. Both approaches let problems slip into production.
Things get worse when people start to feel afraid. Developers start to game the system and split changes into tiny, hard-to-review chunks just to look productive. Others avoid honest feedback because they don’t want to be “that person” who slows down releases.
This is exactly what W. Edwards Deming warned about: “whenever there is fear, you get the wrong numbers.” And when people feel threatened, they polish their image instead of their code.
What these teams need is psychological safety — the shared belief that everyone can speak up, make mistakes, and take risks without facing judgment or retaliation.
But unfortunately, things have gotten so bad in certain places that developers are even afraid to discuss this during job interviews:

(Source)
Engineers post these questions because they worry that showing concern about team culture will hurt their chances of getting hired.
Google studied this exact problem. Their researchers spent two years analyzing 180 teams to figure out what made some successful while others struggled.
They found that psychological safety is the single most important factor for team success. Teams with higher psychological safety lost fewer people, brought in more revenue, and executives rated them as effective twice as often.
Recent research backs this up specifically for software teams. A 2024 study in Empirical Software Engineering found that psychological safety directly advances teams’ ability to pursue software quality. When developers feel safe, they speak up about potential issues more freely and debate solutions.
Here’s how this sounds in practice:
| Instead of this (fear-based) | Try this (safety-based) |
| “Why didn’t you think of this obvious edge case?” | “I wonder if we should handle this edge case — what do you think?” |
| “This is the wrong approach entirely.” | “I’ve tried a similar approach before and ran into X issue. Have you considered Y instead?” |
| “Did you even test this?” | “I’m seeing a potential issue with the error handling here. Can you walk me through how you tested it?” |
This cultural change in the organization structure makes every other code review improvement possible. Without psychological safety, your process changes will just create new ways for people to game the system.
2. Use Checklists to Standardize Expectations
2. Use Checklists to Standardize Expectations
Code review checklists are structured lists of items that reviewers should verify before they approve changes. Just like hospitals and airlines use checklists to prevent fatal errors, code reviews need the same systematic approach.
Different types of checklists target specific risk areas:
- Security checklists focus on vulnerabilities like injection attacks and data exposure
- Performance checklists outline messy queries and memory leaks
- Testing checklists make sure you have good test coverage and capacity planning
- Accessibility checklists verify screen reader support and keyboard navigation
- Logic checklists verify error handling and edge cases
- Documentation checklists verify API docs, README updates, and inline comments
- Deployment checklists confirm environment configs and database migrations
Most teams will benefit from separate checklists for each category rather than one massive list.
Here are two examples of what good checklists look like when you make them specific and actionable:

This frontend checklist covers React-specific issues like proper state management and component structure, plus the universal UI that users notice (e.g., loading states, error handling, and performance).
Notice how each item tells you exactly what to check instead of vague advice like “make it performant.”

This backend checklist focuses on the things that tend to break late at night — security holes, database problems, and error handling. Each item is specific enough that you can check it off quickly.
Just make your checklists easy to find. Add them to pull request templates, pin them to your team’s Slack channel, or bookmark shared documents.
If people have to hunt for your checklist, they won’t use it.
3. Encourage Author Self-Review as the First Line of Defense
Many developers hit “commit” the moment their code compiles and tests pass. They’re eager to move on to the next task or get their changes into review.
But rushing through means missing obvious problems that a quick self-review would catch.
Nobody can review code as effectively as the person who wrote it. They know what the code is supposed to accomplish, understand the business context, and can spot gaps between intent and implementation faster than any reviewer.
Here’s what effective self-review looks like:
- Step away from your code for at least 15 minutes before reviewing it
- Read through the entire diff as if you’re seeing it for the first time
- Check that your changes solve the original problem or ticket requirements
- Run through edge cases and error scenarios in your head
- Double-check that your tests are testing the right things
Here’s how one experienced developer describes their systematic approach:

(Source)
Make self-review part of your standard workflow. Set up git hooks that show you the diff before commits, or use IDE plugins that remind you to pause before pushing.
The small time investment up front saves hours of back-and-forth later. Plus, it makes you a better developer in the process.
4. Keep Reviews Small and Focused
4. Keep Reviews Small and Focused
The largest code review study ever shows why big reviews fail. SmartBear spent 10 months analyzing 2,500 reviews covering 3.2 million lines of code at Cisco Systems.
They found that reviewers spot defects most effectively when examining 200-400 lines of code at a time. And once reviews grow past 400 lines, defect detection starts to drop off.
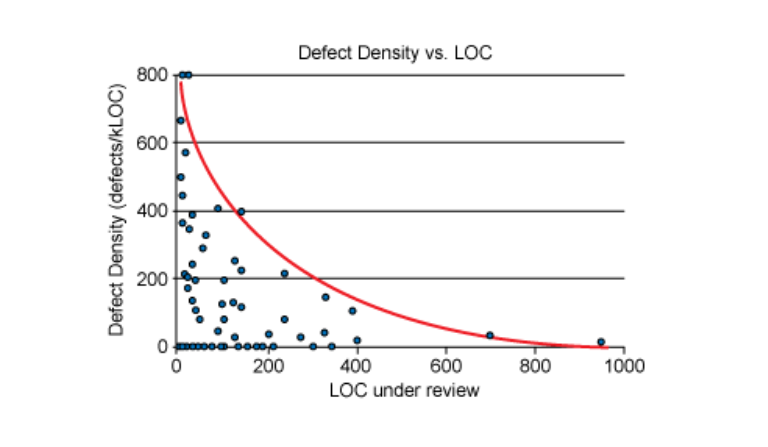
(Source)
When reviewers see thousands of lines of changes, they can’t examine every line carefully. They start skimming instead of reading closely. They miss edge cases and lose track of how changes affect the rest of the codebase.
Teams often struggle to break down large changes, but these strategies make the process much simpler:
- Split by system boundaries: Review API changes separately from database changes, frontend separate from backend.
- Separate cleanup from new features: Submit refactoring and code cleanup first, then build new functionality on the clean foundation.
- Use stacked pull requests: Break features into logical steps where each PR builds on the previous one.
- Deploy behind feature flags: Hide incomplete work models so teams can review and integrate smaller pieces without affecting users.
- Keep related files together: Group changes that affect the same component, but separate unrelated edits.
- Submit infrastructure changes first: Get configuration updates, database schemas, and tooling changes reviewed before the code that depends on them.
Some changes genuinely can’t be broken down. For example, database migrations, major architecture changes, or library upgrades.
For these big reviews, add comments to explain what changed, organize the review into clear sections, and schedule focused sessions where the team won’t get interrupted.
Your developers might complain about splitting up their work, but here’s how to handle their pushback:
- “It takes too long to break things down.” → The time spent splitting changes is recovered multiple times over through faster review cycles, fewer revision rounds, and easier debugging when issues come up.
- “The changes are too interconnected.” → Start with preparatory refactoring to create cleaner boundaries, then implement features gradually. Truly interconnected changes are rarer than they appear.
- “We need this feature complete in one PR.” → You can still deliver complete features using feature flags and stacked PRs while keeping each review small and manageable.
Small reviews get a faster turnaround because they’re less intimidating for reviewers to start. Junior developers can follow the logic without getting lost in huge diffs. And when something breaks, smaller changes are much easier to revert.
5. Limit Both the Pace and Duration of Reviews
5. Limit Both the Pace and Duration of Reviews
Your brain isn’t built for marathon code review sessions. Research from SmartBear’s Cisco study also found that defect detection rates plummet after 60-90 minutes of continuous review time.
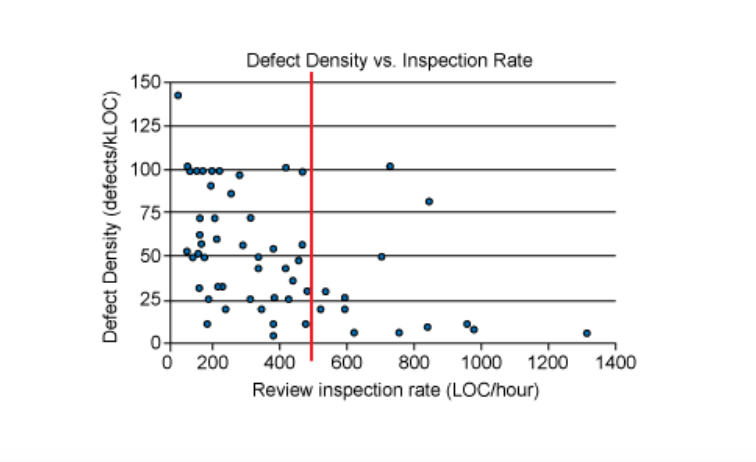
(Source)
Other studies show that 90 minutes of demanding cognitive tasks leads to measurable mental fatigue and performance decline.
The pace matters just as much as the duration. Teams that rush through reviews at more than 500 lines of code per hour usually miss more defects than those that maintain a steady 300-500 LOC per hour.
Review fatigue shows up in predictable ways. Watch for these warning signs that your team is pushing too hard:
- Reviews consistently take a few hours without breaks
- Approval times are getting faster, but post-review bug reports are increasing
- Reviewers complain about feeling overwhelmed or rushed
- Comments focus mainly on formatting and style rather than logic and design
- The same types of issues keep making it to production despite being “reviewed”
When you notice these symptoms, slow down. Better to have thorough 45-minute reviews than superficial 90-minute ones. Your reviewers will catch more specific problems and feel less burned out by the process.
PRO TIP 💡: Jellyfish’s Life Cycle Explorer shows you exactly how long reviews take and whether they’re getting rushed. If your team consistently spends over 90 minutes per review or races through at 600+ lines per hour, you’ll see it in the data and can adjust before quality suffers.

6. Define a Clear Process for Fixing Defects
6. Define a Clear Process for Fixing Defects
Code reviews go off the rails when nobody knows how to handle defects.
Reviewers leave notes like ‘this doesn’t look right,’ authors claim every issue is minor, and actual bugs get lost in endless back-and-forth about what counts as a real problem.
Part of the confusion comes from treating all defects the same way. But defects found during code review are completely different from the ones found in production.
These pre-release defects (e.g., logic errors, security vulnerabilities, performance problems) are your early warning system. They’re still in the developer’s working memory, and fixes are quick.
Post-release bugs found by QA or in production require different tracking systems, involve hotfixes, and may need customer communication. IBM’s research shows that fixing a defect during code review costs 10-100 times less than fixing it in production.
Start with a clear classification system that can prevent endless debates:
| Severity | Action required | Examples | Response time |
| Critical | Blocks merge | Security holes, data corruption risks, and breaking API changes | Within hours |
| Major | Fix before merge | Logic errors, missing error handling, and performance issues | Within 1-2 days |
| Minor | Can defer | Code style inconsistencies, non-critical optimizations, and documentation gaps | Next software development cycle |
The reviewer marks a severity level, but if the author disagrees, they can propose a different classification with a clear explanation. If they still can’t agree after one round, a technical lead makes the final call (this should be rare).
7. Introduce and Track Key Code Review Metrics
7. Introduce and Track Key Code Review Metrics
Most teams either waste time on vanity metrics or track nothing at all. They count completed reviews and measure average times, but ignore whether their process outlines real bugs or just slows down shipping.
The right metrics show you if reviews are worth the time they take. Here’s a breakdown of some of the most useful metrics you should keep an eye on:
| Metric | What it measures | Why it matters |
| First response time | Hours from PR opened to first meaningful review comment | Long waits kill developer momentum and delay features |
| Review turnaround time | Total amount of time from PR creation to approval | Shows if reviews are blocking the deployment pipeline |
| Review depth | Lines of effective code reviews per hour (target: 300-500) | Too fast means skimming, too slow means inefficiency |
| Defect detection rate | Bugs caught in review vs. bugs that escape to production | Proves if reviews actually improve quality code |
| Review distribution | Percentage of reviews done by each team member | Outlines bottlenecks and knowledge silos |
| Rework rate | PRs requiring 3+ rounds of changes | Signals messy requirements or communication issues |
| Comment quality ratio | Substantive comments vs nitpicks/style issues | Shows if reviews focus on what matters |
| Author response time | Hours from review comment to author’s fix | Reveals if authors treat feedback urgently |
| Post-review incident rate | Production issues in recently reviewed code | Ultimate measure of review effectiveness |
Your goal with these metrics isn’t to judge individual developers, but to spot blockers and optimize your process.
For example, long review cycles usually mean PRs are too big or some teammates are drowning in review requests. Lots of rework often shows that authors aren’t reviewing their own code carefully enough, or your team needs clearer coding standards.
This is where an engineering management platform like Jellyfish can automatically pull this data and show you patterns across your whole development process. You get unbiased data instead of manual spreadsheets that nobody maintains.
8. Use the Right Tools to Reinforce Best Practices
8. Use the Right Tools to Reinforce Best Practices
Best practices fail when they rely on human discipline alone. You can’t expect developers to manually check every security rule or remember to update documentation every time.
The right code review tools handle the repetitive checks so humans can focus on architecture and logic.
Here are some popular tools across several categories you can consider:
| Tool category | What it does | Examples | Why it helps |
| Linting tools | Flags syntax errors, unused variables, and code issues | ESLint, Pylint, RuboCop | Linters catch basic mistakes before code review starts |
| Static analysis | Detects complex bugs and security vulnerabilities | SonarQube, Semgrep, CodeQL | Finds race conditions, memory leaks, and logic errors |
| Code formatters | Applies consistent code style automatically | Prettier, Black, gofmt | Removes style debates — code formats on save |
| Security scanners | Checks for vulnerable dependencies and exposed secrets | Snyk, GitGuardian, Dependabot | Prevents API keys and passwords from reaching the repo |
| Coverage tools | Measures which code has unit test coverage | Codecov, Coveralls, built-in IDE tools | Shows untested code paths and edge cases |
| PR automation | Manages review assignments and notifications | GitHub Actions, GitLab CI, Bitbucket Pipelines | Auto-assigns Java reviewers, checks PR size, sends reminders
|
| Documentation generators | Creates API docs from code comments
|
Swagger, JSDoc, Sphinx | Keeps documentation accurate as code changes |
| Analytics platforms | Tracks peer review time and team metrics
|
Jellyfish | Shows where time gets lost in your process |
Tools like Jellyfish show you what’s happening in your review process without anyone having to track it manually.
The dashboard above breaks down where time goes in your development cycle — here you can see 4 days and 4 hours spent in review out of a 33-day total.
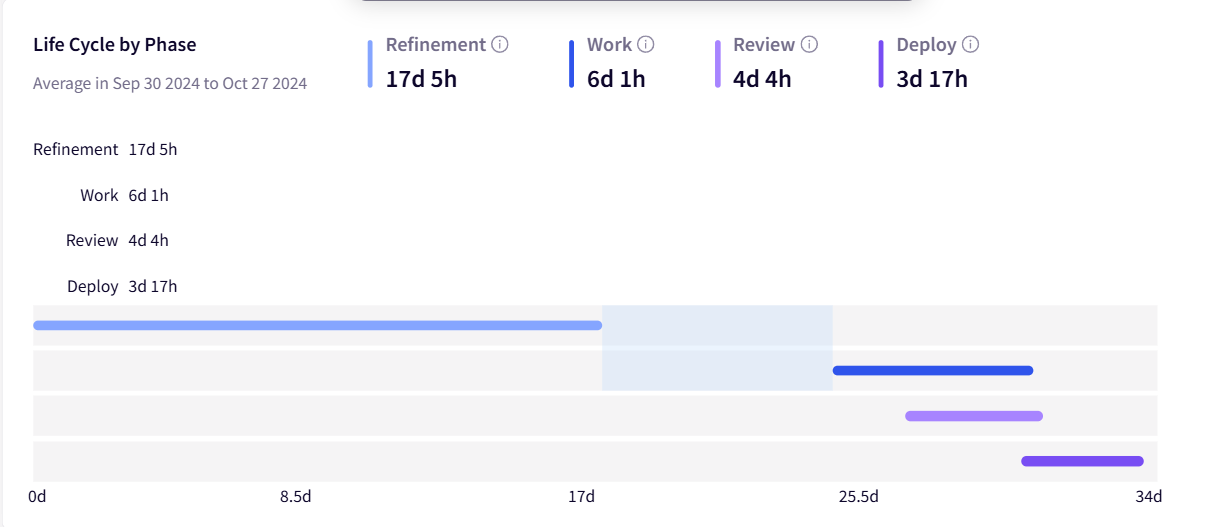
This data helps you figure out if reviews are slowing things down or if the delays happen somewhere else.
9. Automate Objective Quality Checks
9. Automate Objective Quality Checks
Companies that use test automation typically cut their testing cycles by about 25%. That’s time saved on every single pull request, which adds up to weeks of recovered productivity across a team.
Here’s a quick breakdown of what you should automate and what should stay with human reviewers:
| Automate this | Keep this human |
| Code formatting and style | Architecture decisions |
| Test coverage thresholds | Business logic correctness |
| Build success and syntax errors | Code readability and clarity |
| Security vulnerabilities in dependencies | Variable and function naming quality |
| License compliance checks | Performance optimization strategies |
| File size and PR size limits | User experience implications |
| Duplicate code detection | Edge case identification |
| Documentation completeness | Technical debt trade-offs |
And watch out for these common automation mistakes if you’re just getting started:
- Don’t set test coverage at 90% on day one — start at 60% and increase gradually
- Make sure error messages explain what’s wrong and how to fix it, not just “check failed”
- Let programmers override checks for exceptional cases, but make them document why
- Keep automated test checks under 10 minutes, or developers will skip them entirely
- Fix or remove rules that constantly cry wolf (false positives train people to ignore real problems)
With automation handling the mindless checks, you get shorter and more valuable reviews. Developers focus on architecture and edge cases instead of semicolons and spacing.
10. Build a Review Rotation to Spread Knowledge
10. Build a Review Rotation to Spread Knowledge
When the same people review the same piece of code every time, you create knowledge silos. Jane reviews all the backend code, Mike handles the frontend, and nobody else knows how either system works. Then Jane goes on vacation, and backend PRs pile up for two weeks.
Review rotation fixes this problem while making your whole team stronger. Instead of routing all database changes to your database expert, rotate through different reviewers. The expert still weighs in on complex changes, but others learn the codebase too.
Here’s how to make rotation work:
- Pair experienced reviewers with newer team members, so the senior outlines key issues while the junior learns. It’s also a great mentoring opportunity.
- Assign primary and secondary reviewers to each PR, with different people each time
- Set up cross-team reviews monthly so frontend developers understand backend constraints
- Keep a simple spreadsheet tracking who reviewed what for fair distribution
- Let people flag PRs that genuinely need specific expertise
Don’t underestimate junior developers in the review process. As one engineering lead explains on Reddit:

(Source)
Junior reviewers ask the “obvious” questions that seniors skip over. When they can’t understand code, it usually means the code needs better code comments or a simpler structure.
Some code does need specialist review, such as security changes, database migrations, or payment processing. Mark these clearly for follow-up and bring in experts.
But for most changes, fresh eyes from different team members catch problems that regular reviewers miss through familiarity.
The short-term cost is slightly longer reviews as people learn new areas. The long-term benefit is a team that understands the entire system, catches more bugs, and doesn’t grind to a halt when someone’s out sick.
PRO TIP 💡: Jellyfish’s distribution metrics reveal knowledge silos instantly. When you see Jane reviewing 80% of backend PRs, you know exactly where to focus your rotation efforts. You can then track whether your rotation strategy works by watching the distribution even out over time.
From Best Practices to Actionable Insights with Jellyfish
From Best Practices to Actionable Insights with Jellyfish
You’ve implemented all these best practices, but how do you know if they’re working?
Manual tracking through spreadsheets and GitHub reports eats up hours every week, and you still miss important patterns.
And without real data, you can’t outline why delivery slipped last quarter or prove to shareholders that investing in better reviews saves money on production fixes.
That’s where Jellyfish comes in. It’s an engineering intelligence platform that automatically pulls data from your entire toolchain (GitHub, GitLab, Jira, and more) to show you exactly what’s happening in your code review process and across your entire development lifecycle.
Here’s exactly what Jellyfish brings to the table:
- Track exactly where delays happen in your development cycle: Jellyfish’s Life Cycle Explorer breaks down each phase — refinement, work, review, and deployment. You can see if that 4-day review time is your real problem, or if it’s actually the 17 days spent in refinement before writing code.
- Balance review workload before your best reviewers burn out: The resource allocation tool shows you exactly how engineering time gets distributed across different work types and teams. When one developer handles 60% of reviews while others barely participate, you’ll notice it immediately and can redistribute the load.
- Prove AI tools actually improve your code quality: Track whether GitHub Copilot, Cursor, or Gemini produces code that needs fewer review cycles. Jellyfish’s AI Impact metrics show acceptance rates by language and team, so you know if AI-generated code speeds through reviews or creates more rework.
- Build realistic timelines that account for review cycles: Scenario Planner helps you create delivery estimates based on actual historical data, including review times. When the product team asks if that feature will ship in 2 weeks, you’ll know if reviews typically add another week to similar work.
Your code review data is trying to tell you something. Book a demo and get to the bottom of it.
Frequently Asked Questions (FAQ)
Frequently Asked Questions (FAQ)
How do we handle urgent fixes that need to bypass the full review process?
Create a “hotfix” process where one senior engineer does a quick sanity check before merging.
Define what counts as urgent (site is down, security hole, data corruption) and demand a proper review within 24 hours after the fix goes live.
What should we do when reviewers disagree on a change?
Get them talking directly. Most arguments disappear after a 5-minute face-to-face conversation. If they still can’t agree, the person who wrote the source code makes the call since they’ll be maintaining it.
Save technical lead escalation for the rare times when it’s about core architecture.
How can we get senior developers to spend more time reviewing code?
Make reviews part of their actual job, not something they squeeze in between coding. Show everyone the review stats so it’s clear who’s doing the work.
Give seniors the tricky PRs and let juniors handle the simple tasks — everyone’s time gets used better.
How long should a pull request stay open?
Try to merge regular PRs (under 400 lines) within 24 hours. After 3 days, PRs start to rot. The author forgets what they did, merge conflicts appear, and everyone loses interest. If something sits for 2 days without a review, ping your team lead.
Our pull requests are always too big. How do we enforce smaller PRs?
You can set up automatic warnings when PRs hit 400 lines and demand manager approval over 800.
It’s also a good idea to teach developers to use feature flags so they can ship partial work safely. Once they see small PRs getting reviewed in hours instead of days, they’ll start splitting work on their own.
Learn More About Developer Productivity
Learn More About Developer Productivity
- What is Developer Productivity & How to Measure it the Right Way
- What is Developer Productivity Engineering (DPE)?
- 9 Common Pain Points That Kill Developer Productivity
- How to Improve Developer Productivity: 16 Actionable Tips for Engineering Leaders
- Automation in Software Development: The Engineering Leader’s Playbook
- 29 Best Developer Productivity Tools to Try Right Now
- 21 Developer Productivity Metrics Team Leaders Should Be Tracking
- AI for Developer Productivity: A Practical Implementation Guide
- How to Build a Developer Productivity Dashboard: Metrics, Examples & Best Practices
- Developer Burnout: Causes, Warning Signs, and Ways to Prevent It
- Mitigating Context Switching in Software Development
About the author

Lauren is Senior Product Marketing Director at Jellyfish where she works closely with the product team to bring software engineering intelligence solutions to market. Prior to Jellyfish, Lauren served as Director of Product Marketing at Pluralsight.