In this article
For the last decade, DevOps has been the gold standard for engineering culture. By breaking down the silos between development and operations, organizations aimed to ship software faster and more reliably.
But success created a new problem: the DevOps Paradox. [*]
In the rush to shift left, organizations shifted immense complexity onto their application developers. The mantra “you build it, you run it” often evolved into “you build it, you run it, you secure it, and you debug the Kubernetes cluster.” Today, highly skilled developers spend hours wrestling with infrastructure configuration instead of writing product code. This cognitive load is slowing teams down and fueling burnout.
Platform engineering is the next necessary evolution to solve this problem. It doesn’t replace DevOps; it scales it.
By treating internal infrastructure not as a mess of tickets and scripts, but as a compelling Internal developer platform (IDP), platform engineering restores developer focus. It provides the golden paths that allow teams to self-service their needs instantly.
Here are the 8 ways platform engineering solves these problems and drives real business value.
1. Boosting Developer Productivity via Self-Service Platform
1. Boosting Developer Productivity via Self-Service Platform
In many organizations, high-velocity software engineering teams hit a wall the moment they need infrastructure. A developer finishes writing code, but then enters the world of TicketOps—filing a ticket and waiting days for a central operations team to provision a database, open a firewall port, or spin up a testing environment. [*] This stop-and-start development workflow destroys momentum.
Platform engineering removes this friction by providing self-service capabilities. An internal developer platform (IDP) offers an automated interface—like a developer portal or CLI—where developers can provision approved resources instantly.
2. Reducing Cognitive Load and Burnout
2. Reducing Cognitive Load and Burnout
Modern cloud-native development is incredibly complex. Developers are often forced to become experts in the entire stack—wrestling with Terraform state files, Helm charts, networking rules, and IAM policies just to ship a feature. This high cognitive load leads to decision fatigue, lower quality code, and eventually, burnout.
A platform solves this through abstraction layers. The platform team hides the complexity behind a simple interface. A developer shouldn’t need to know how a database is backed up, encrypted, and replicated; they just need to be able to request a Postgres database.
- The impact: Improved developer experience (DevEx) and talent retention. Your senior engineers can stay focused on product innovation and business logic rather than getting bogged down in infrastructure plumbing.
Learn more → 7 Warning Signs of Engineering Burnout
3. Accelerating Time-to-Market (TTM)
3. Accelerating Time-to-Market (TTM)
Every time a team starts a new microservice or feature, they face the blank page problem. They waste days—sometimes weeks—scaffolding the repository, figuring out the right CI/CD configuration, and setting up boilerplate code. This infrastructure tax is a major drag on velocity.
Platform engineering solves this through golden paths. Instead of starting from scratch, developers use pre-configured templates for common service types. A developer can select a “Spring Boot Microservice” template, and within minutes, they have a “Hello World” service that is fully containerized, integrated into the software delivery pipeline, and deployed to a staging environment.
- The impact: Drastic reduction in lead time for new features. The organization moves from idea to production significantly faster, allowing the business to test hypotheses and iterate on product features sooner.
Example: Imagine a fintech company where launching a new service used to require three weeks of security reviews and infrastructure setup. By implementing a platform with compliant-by-default templates, they reduced that lead time to 20 minutes. This agility allows the business to test hypotheses and iterate on product features drastically faster.
4. Enforcing Standardization and Consistency
4. Enforcing Standardization and Consistency
Without a platform, you inevitably end up with snowflake infrastructure. Team A uses CircleCI, Team B uses Jenkins; one team logs to Splunk, another to Datadog. This fragmentation makes debugging a nightmare and prevents engineers from easily moving between teams.
A platform drives consistency not by writing rules on a wiki, but by making the standard way the easiest way. When every new service is born from a platform template, they all share the same architectural DNA—standardized logging, monitoring, and directory structures.
- The impact: Reduced technical debt and easier internal mobility. Engineers can switch teams and understand the stack immediately, and the platform team can roll out global updates (like a library patch) instantly across all services.
Avoid this trap: Do not confuse standardization with restriction. If your platform is too rigid and prevents teams from using the necessary set of tools (e.g., forcing a data science team to use a web service template), they will simply bypass it. The goal is to pave the most common roads, not to ban off-roading entirely.
5. Strengthening Security and Governance (DevSecOps)
5. Strengthening Security and Governance (DevSecOps)
In traditional models, security is often a manual gate at the end of the process. This creates an adversarial relationship where security teams are seen as blockers who slow down releases. Or worse, developers under pressure bypass security checks entirely to meet deadlines.
Platform engineering shifts this dynamic by baking Policy-as-Code directly into the development workflow. The platform can automatically ensure that every deployment meets regulatory standards (like encryption at rest or RBAC configuration) before it ships.
Pro Tip: Configure your platform to automatically scan dependencies and container images every time code is committed. If a vulnerability is found, block the build and notify the developer immediately. This creates a fast feedback loop where security is handled during development, not weeks later during an audit.
6. Streamlining Onboarding for New Engineers
6. Streamlining Onboarding for New Engineers
The cost of hiring is high, but the cost of a slow ramp-up is higher. In many organizations, new hires spend their first month fighting to set up local development environments, hunting for access keys, and reading outdated documentation.
A mature IDP transforms onboarding into a Day 1 win. By providing cloud-based development environments or standardized configuration scripts, a new hire can pull down the codebase and deploy a change on their very first day.
To maximize this benefit, your platform should allow a new hire to do the following without asking for help:
- Access the code repository and documentation.
- Provision a personal development environment.
- Run the test suite locally.
- Deploy a minor change to a staging environment.
7. Optimizing Cloud Costs
7. Optimizing Cloud Costs
Cloud waste is rarely intentional; it’s usually the result of friction. Developers spin up test environments and forget to turn them off because it’s too hard to spin them up again. Or they provision oversized instances because they don’t have the visibility to right-size them.
Internal platforms introduce automated lifecycle management. You can set policies where ephemeral environments automatically spin down after 24 hours or when a pull request is merged.
This prevents zombie infrastructure from eating up your budget. By centralizing resource provisioning, the platform team can enforce cost-efficient architecture defaults across the organization.
8. Enabling Scalability Without Chaos
8. Enabling Scalability Without Chaos
In early-stage startups, reliability often depends on heroics—a few senior engineers who know exactly how to fix the system when it breaks. This doesn’t scale. As you add more developers, you cannot afford to add linearly more operations staff to support them.
Platform engineering enables non-linear growth. By automating the operational complexity—scaling clusters, managing backups, and handling failovers—the platform allows your organization to double its engineering headcount without doubling the operational chaos. It codifies the hero knowledge into software that runs automatically.
Why Some Platform Initiatives Fail (And How to Avoid It)
Why Some Platform Initiatives Fail (And How to Avoid It)
Building a platform is a high-stakes investment. It is not just a technical project; it is an internal product launch. Despite the clear benefits, many platform initiatives struggle to gain traction. Leaders must be aware of the three common traps that lead to failure.
The Field of Dreams Fallacy
Engineering leaders often assume they know exactly what their developers need. They build a massive, complex platform in isolation for 12 months, assuming that “if they build it, developers will come.” When they finally launch, they find that no one wants to use it because it doesn’t solve the actual day-to-day friction developers face.
The solution:
Treat the platform as a product. Before writing code, conduct user research with your developers. Build a Minimum Viable Platform (MVP) that solves one specific pain point, release it to a pilot group, and iterate based on real feedback.
The Golden Cage
To ensure ROI, leadership mandates that everyone must use the new platform by shutting off access to other tools. This breeds resentment, hides critical feedback, and encourages shadow IT where teams build secret workarounds to bypass the platform.
The solution:
Make adoption voluntary. The platform should be the path of least resistance—so good that developers choose it because it makes their lives easier, not because they are forced to. If teams aren’t adopting it, treat it as a bug in the product, not a compliance issue with the team.
Learn more → This guide breaks down 8 clear signs your organization needs platform engineering now (if you recognize most of them, you’ve probably outgrown your current infrastructure).
Over-Engineering
The platform team tries to abstract away everything at once, creating a rigid black box. This often leads to a leaky abstraction where the platform layer breaks, and developers can’t debug the underlying issue because they are locked out of the infrastructure.
The solution:
Start with the thinnest viable platform (TVP). Don’t try to hide all complexity immediately. Solve one major pain point exceptionally well (e.g., “Deployments are too slow”) before expanding. Allow for off-roading so advanced teams aren’t blocked by the platform’s limitations.
Ensure Your Platform Strategy Succeeds with Jellyfish
Ensure Your Platform Strategy Succeeds with Jellyfish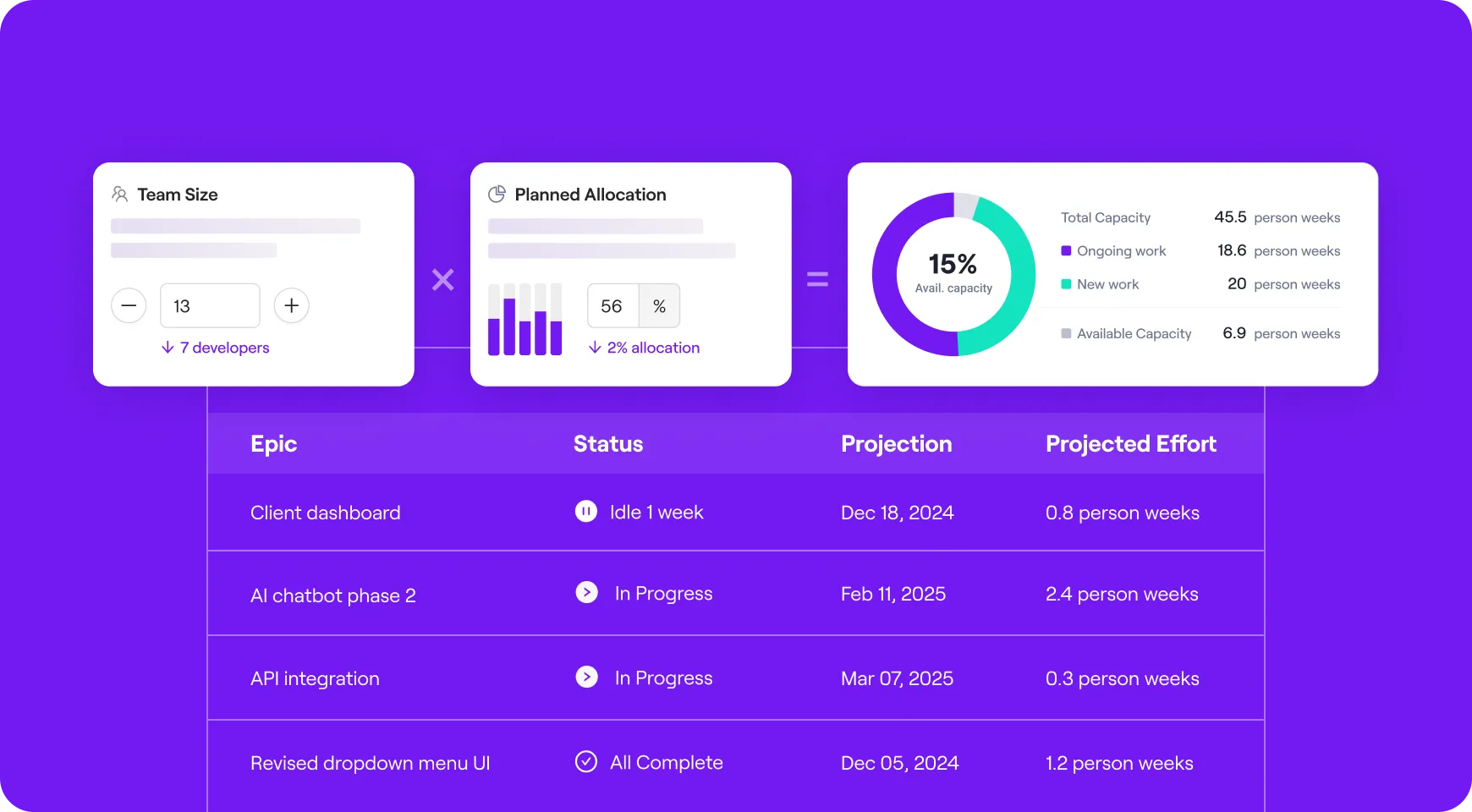
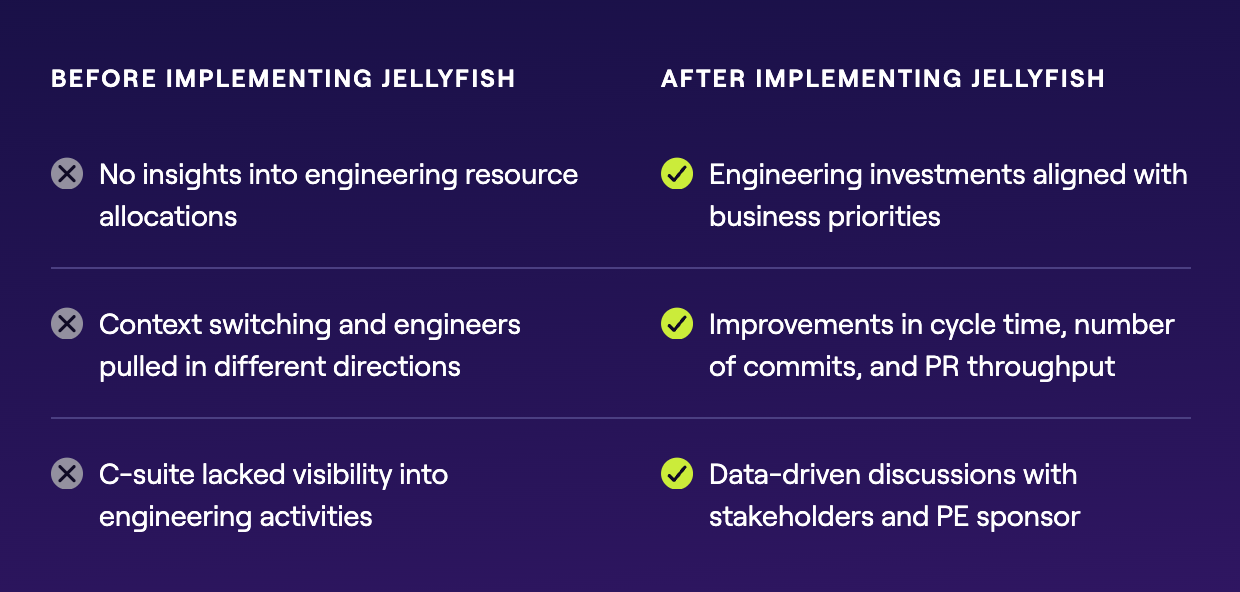
Investing in platform engineering is a strategic bet. You are dedicating significant resources to build an internal product. To ensure this bet pays off, you need visibility into how it is reshaping your engineering organization.
Jellyfish provides the strategic alignment and visibility leaders need to manage this transition effectively.
- Verify the shift in focus: A successful platform should liberate developers from toil. Use the capacity planner and resource allocation data to verify that your teams are actually spending less time on underlying infrastructure/support tasks and more time on roadmap/strategy after adopting the platform.
- Validate the efficiency gains: Don’t just guess that the platform is making you faster. Track cycle time trends across the organization to see if the teams using the platform are delivering value faster than those who aren’t.
- Monitor adoption and impact: Understand which teams are adopting the new workflows and how that correlates with their operational health, allowing you to make data-driven decisions on where to invest next.
Hear it from our friends at Quantexa, who used Jellyfish to gain the visibility needed to align their engineering resources with their strategic business goals.
Using Jellyfish allows us to answer questions around developer efficiency and effectiveness and be able to report on it over time to spot trends and issues.
– Jamie Hutton, Chief Technology Officer at Quantexa
To learn more about Jellyfish, request a demo today.
FAQs
FAQs
What core technologies does a platform usually abstract?
Platforms often abstract the complexity of cloud providers (like AWS) and container orchestration. They provide reusable templates for infrastructure as code (IaC) and pre-configured CI/CD pipelines, connecting various toolchains via APIs to deliver seamless functionality to developers.
How does platform engineering impact DevOps teams and SREs?
Instead of handling repetitive tickets, DevOps teams evolve into platform engineers who build self-service tools. This reduces toil for SRE (Site Reliability Engineering) by ensuring production environments and workloads are deployed with consistent observability and reliability standards baked in.
How does an IDP improve software quality and security?
By standardizing deployment processes, the internal platform ensures that all code goes through rigorous testing and security checks. It manages permissions and governance automatically, which improves overall software quality and gives stakeholders confidence in the system’s stability.
What metrics should I track to prove the value of my IDP?
Focus on metrics that show velocity and efficiency, such as the speed of development cycles and deployment frequency. You should also measure the reduction in time spent on infrastructure setup versus feature development to demonstrate the ROI of your investment.
Learn More About Platform Engineering
Learn More About Platform Engineering
- The Complete Guide to Platform Engineering
- Platform as a Product: The Foundation for Successful Platform Engineering
- When to Adopt Platform Engineering: 8 Signs Your Team is Ready
- Platform Engineering vs. DevOps: What’s the Difference?
- How to Build a Platform Engineering Team: Key Roles, Structure, and Strategy
- Understanding The Platform Engineering Maturity Model
- How to Build Golden Paths Your Developers Will Actually Use
- Best 14 Platform Engineering Tools Heading Into 2026
- 17 Platform Engineering Metrics to Measure Success and ROI
- 9 Platform Engineering Anti-Patterns That Kill Adoption
- The Top Platform Engineering Skills Every Engineering Leader Must Master
- 11 Platform Engineering Best Practices for Building a Scalable IDP
- What is an Internal Developer Platform (IDP)?
About the author

Lauren is Senior Product Marketing Director at Jellyfish where she works closely with the product team to bring software engineering intelligence solutions to market. Prior to Jellyfish, Lauren served as Director of Product Marketing at Pluralsight.




