In this article
You’re considering platform engineering. Maybe you’ve seen the success stories, heard about faster deployments, and happier developers. But before you commit budget and headcount, you need to understand what you’re signing up for.
Platform engineering isn’t binary. You don’t just “do platform engineering” and check a box. Organizations move through maturity stages, and where you start (and where you aim) depends on your size, complexity, and current capabilities.
The platform engineering maturity model maps this journey. It shows you what basic, intermediate, and advanced platform engineering look like in practice.
This guide explains each stage so you can assess what makes sense for your team and avoid overbuilding or underinvesting.
Why the Maturity Model Matters for Engineering Leaders
Why the Maturity Model Matters for Engineering Leaders
The maturity model gives you a shared language to talk about platform capabilities, a way to set realistic goals, and a framework to measure progress over time.
More specifically, the model helps you in these ways:
- It prevents overbuilding: Early-stage teams sometimes try to copy what Google or Netflix built, then wonder why developers ignore their fancy internal platform. The model shows you what capabilities match your current scale and complexity.
- It clarifies what “platform engineering” means for your org: The term gets thrown around to mean everything from CI/CD to cloud automation. The model defines what you’re building and keeps everyone on the same page.
- It helps you prioritize investments: You can’t build everything at once, nor should you. With 69% of developers losing 8+ hours weekly to inefficiencies, the wrong priorities mean money walking out the door. The model shows which capabilities bring the most value at your current stage, so you’re not guessing what to fund next.
- It aligns leadership on expectations: Executives want to know when they’ll see ROI and what “done” looks like. The model gives you milestones you can point to and explain why certain capabilities come before others.
- It improves developer experience (DevEx): Your developers already have enough tools and workflows to navigate. The model shows you which features reduce cognitive load and give developers the speed and autonomy they want. This matters especially when you consider that nearly two in three developers consider quitting over a poor developer experience.
- It makes the case for resources: When you can show leadership where you are, where similar companies are, and what it takes to move forward, budget conversations get easier. The model turns “we need more people” into “here’s what we can do with the right investment.”
- It helps you benchmark against peers: You can compare your platform capabilities to other organizations at a similar scale and see where you’re ahead or behind. The model gives you context for whether you’re competitive, especially as Gartner predicts 80% of large software engineering organizations will have platform teams by 2026.
The 5 Stages of Platform Engineering Maturity
The 5 Stages of Platform Engineering Maturity
Platform engineering maturity follows a predictable path. Organizations start with manual operations and progress toward fully automated, self-service platforms.
Understanding these stages helps you see where you are and what comes next:
Stage 1: Ad-Hoc
This is where most organizations start. Developers handle infrastructure tasks manually, operations teams respond to requests one by one, and nothing is standardized or repeatable. One engineer on Reddit described how this usually plays out:

Key characteristics:
- Developers send Slack messages or emails to get access to environments, deploy code, or change configurations
- Every engineer has their own way of deploying or setting up services, and none of them match
- When something breaks in production, you scramble to find the person who set it up or made the last change
- Documentation exists, but nobody trusts it because it’s outdated the moment someone writes it down
- Engineers spend half their week waiting for access, fixing environments, or figuring out how to deploy
- New hires ask the same questions everyone has asked before them because there’s no single source of truth
What you have at this stage: You have servers, cloud accounts, and applications running in production. You probably have some scripts or runbooks, but they’re inconsistent, and people don’t always use them. Most work happens through direct access, manual changes, and tribal knowledge.
What’s missing: You don’t have automation, standards, or repeatable processes. Infrastructure provisioning needs human intervention every time. Developers can’t self-serve, so they wait on ops teams, and ops teams become bottlenecks. There’s no consistency across environments or dedicated teams.
Typical organization profile: Early-stage startups and small teams (under 20 engineers) usually operate at this stage. They move fast by doing things manually, and they haven’t hit the scaling pain that forces them to invest in platform capabilities.
Stage 2: Standardization
You’ve recognized that manual operations don’t scale, so you start to document processes and build basic automation. Infrastructure as code (IaC) enters the picture, and teams begin to standardize how they deploy and manage resources.
Key characteristics:
- Your team uses Infrastructure as Code tools like Terraform, Kubernetes, or CloudFormation to define and provision resources
- CI/CD pipelines handle some deployments automatically instead of relying on manual intervention every time
- You have documentation that people reference and update, even if it’s not perfect or complete
- A few people on the team write scripts to automate repetitive tasks like environment setup or database migrations
- You’ve standardized on specific tools and frameworks, so most projects follow similar patterns
What you have at this stage: You have basic automation in place. Teams use Infrastructure as Code to provision resources, so there’s a record of what exists and how it’s configured. CI/CD pipelines handle common deployment scenarios, and documentation covers the most frequent tasks. New engineers can find answers without hunting down the one person who knows how everything works.
What’s missing: Automation exists, but it’s incomplete. Different teams still use different tools or maintain their own scripts. Developers can’t self-serve because they still need help from ops or platform teams to get things done. You don’t have a unified platform or portal where developers can provision resources, check status, or troubleshoot issues on their own.
Typical organization profile: Growing companies with 20-50 engineers typically reach this stage when manual operations become too painful. They’ve hired dedicated ops or platform engineers who start building automation and pushing for standards.
Stage 3: Automation
You’ve reached a point where automation runs most of your infrastructure workflows. Developers get what they need through self-service interfaces, and the platform team builds features and fixes bottlenecks instead of responding to individual tickets.
Key characteristics:
- Developers create databases, spin up services, and configure infrastructure through platforms (no waiting for ops teams)
- Your CI/CD system handles the entire deployment flow, tests changes automatically, and reverts bad releases without human intervention
- Developers access dashboards and logs directly, so they debug their own services without escalating
- The platform team maintains shared templates and modules that let developers launch new services in minutes
- Most teams follow golden paths for common patterns like API deployments or database setup because they’re easier than custom solutions
What you have at this stage: You have a functional internal platform that automates most routine tasks. Developers can deploy code and provision infrastructure without waiting on other teams. Onboarding is fast because new engineers can use self-service tools immediately.
What’s missing: Self-service is limited to predefined paths and common scenarios. When developers need something outside the golden path, they still escalate to the platform team. You don’t have strong governance or policy enforcement, so teams can still diverge or make changes that lead to pain points later.
Typical organization profile: Companies with 50-150 engineers usually reach this stage after they’ve built a dedicated platform team. Developers can work independently for most tasks, and the platform scales well enough to support multiple product teams.
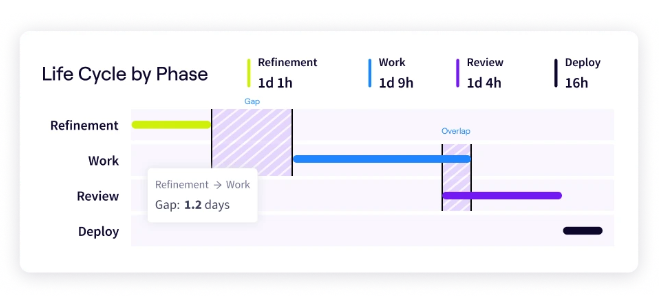
PRO TIP 💡: Once automation is in place, you need to know if it’s working. Jellyfish’s Life Cycle Explorer maps where work gets stuck in your development process, so you can focus platform improvements on the bottlenecks that slow teams down.
Stage 4: Integration
You have an integrated platform that ties your tools together. Governance runs automatically, the system responds to usage patterns, and developers get one unified user experience across deployments, monitoring, security, and everything else.
Key characteristics:
- Security policies, cost limits, and compliance rules run automatically as part of the platform instead of as separate checks
- Your internal developer platform unifies tools and workflows into a single interface where developers manage everything from code to production
- Developers get contextual recommendations and guardrails that guide them toward best practices without blocking their work
- Platform APIs and integrations connect to your entire toolchain, so developers don’t switch between disconnected systems
- Your platform team operates like a product team with roadmaps, user research, and metrics that track developer satisfaction and productivity
What you have at this stage: You have a platform people trust. One system handles what developers need, keeps standards in place without being annoying about it, and shows helpful info at the right time. It adapts when things change, and you streamline it based on what people say and what the numbers show.
What’s missing: The platform is mature but not fully optimized. Teams still coordinate manually because the platform doesn’t help them share knowledge or reuse each other’s work. Innovation happens within teams but doesn’t spread systematically across the organization.
Typical organization profile: Large organizations with 150-500 engineers typically operate at this stage. They’ve invested heavily in platform engineering initiatives for several years and treat their internal platform as seriously as any customer-facing product. As one Reddit user cautioned:
If you’re serious about a platform engineering journey, you’ll need to embrace the fact that it’s basically equivalent to establishing another scalable product team and will require traditional software engineering.
If you’re not comfortable with this current state, I would caution against going too much farther without thinking it through some more.
Stage 5: Optimization (The Platform as a Product)
This is the highest level of platform engineering maturity. Your platform works as a living system that improves itself based on what it learns from your teams. Knowledge moves between groups automatically, and you measure success through business outcomes like feature velocity and customer impact.
Key characteristics:
- The platform watches how teams work, spots where they slow down, and adjusts workflows to remove friction
- When one team builds something reusable, others discover it through the platform instead of Slack or wiki pages
- Developers get contextual recommendations during their work based on what’s worked well across thousands of deployments in your organization
- Metrics connect to business outcomes like shipping speed and the value delivered to end users (not just technical stats like uptime)
- The platform tests changes to its own functionalities and keeps the ones that make developers more productive
What you have at this stage: Your platform is organizational infrastructure now. It learns from every team’s work and gets better continuously. Solutions spread across the org automatically, developers benefit from what others learned without coordination overhead, and metrics track business value.
What’s missing: Nothing major is missing. The focus moves from creation to maintenance. You keep the platform strong as your organization expands and technology evolves. The hard part is to keep the platform relevant as business priorities change, new tools appear, and your organization scales up.
Typical organization profile: The largest tech companies with 500+ engineers operate here. They’ve invested in platform engineering for years, run teams of dozens of platform engineers, and treat their internal platform as a competitive advantage that enables everything else they do.
Spotify is a clear example. Their internal platform org includes 75+ engineers who operate as maintainers for Backstage and the developer experience ecosystem that powers hundreds of product teams.
PRO TIP 💡: At this level, operational metrics aren’t enough. Jellyfish ties engineering work to business outcomes like feature velocity and customer impact, so you can prove your platform is a strategic asset, not just infrastructure.
How to Measure Your Maturity and Guide Your Strategy
How to Measure Your Maturity and Guide Your Strategy
You need an honest assessment of where you stand before you can plan where to go next. Here’s how to diagnose your current level of maturity and use that to create a more practical roadmap:
- Can developers deploy code to production without filing a ticket or waiting for someone else?
- Do you have Infrastructure as Code (IaC) for most of your environments, or do people still make manual changes?
- When a new engineer joins, can they ship code in their first week using self-service tools?
- Do you apply standards through automation, or do you rely on documentation and code reviews to catch drift?
- Can you measure how your platform affects developer productivity and business goals?
- Does knowledge spread across teams automatically, or does it stay trapped in Slack threads and individual heads?
If most answers are no, you’re likely at Stage 1 or 2. You have gaps in automation and self-service that block developers and create bottlenecks.
If you answered yes to the first few but no to the rest, you’re probably at Stage 3. Your automation is solid, but integration and governance need more attention. Mostly yes means Stage 4 or 5. The platform is mature, and you’re in optimization mode.
Don’t try to jump two stages at once. Platform maturity needs an iterative approach. When you try to jump ahead, you skip foundational work that becomes a problem later. Build what matters at your current level first.
And keep in mind that moving one stage takes most organizations around 6-12 months. Smaller teams can move faster, while larger organizations with legacy systems take longer.
So, don’t tell your CTO you’ll hit Stage 4 by next quarter – you’ll lose credibility when you miss the target and burn out your team in the process. Set realistic timelines and show consistent progress.
How to Advance Through the Maturity Model
How to Advance Through the Maturity Model
Assessment tells you where you are, but now you need a plan to get where you want to go. These are the key actions that move you from one stage to the next:
Stage 1 to 2: Automate the Basics
Your goal at this stage is to replace manual work with repeatable processes. You don’t need a fancy platform yet. You need automation that works without tribal knowledge or one person being available to run it.
This is where you can start:
- Pick one high-pain workflow and automate it first. Deployments are usually the best place to start because everyone feels that friction daily
- Set up Infrastructure as Code (IaC) for your core environments. Terraform, Pulumi, AWS CloudFormation, or Microsoft’s Bicep are the usual go-to options (pick one and standardize on it)
- Set up a basic CI/CD pipeline that runs tests and deploys code without manual steps
- Move configuration out of people’s heads and local machines into version control, where everyone can see it
Don’t try to automate everything at once. Teams that go too broad end up with half-finished automation across ten workflows instead of solid automation for two or three. Pick your battles and finish them.
And don’t build custom tools when off-the-shelf options work fine. At this stage, you need speed and reliability, not perfect customization.
How to know you’re ready for Stage 3: Developers can deploy code through a pipeline without filing tickets. New engineers can follow documented processes to do common tasks without asking someone to walk them through it. When you hit these marks, you’re ready to focus on self-service and golden paths.
Stage 2 to 3: Set up Self-Service Capabilities
Your automation works. Now, you need to make it accessible so developers can use it on their own. When developers file tickets or send Slack messages for routine tasks, that’s a bottleneck. Self-service lets developers handle things directly. But don’t underestimate the work involved. As one Reddit user put it:

Your priorities:
- Build golden paths for your most common use cases. If teams spin up new services regularly, give them a template that handles 80% of the setup automatically
- Create an internal portal or CLI where developers can provision resources, launch deployments, and check status without involving another team
- Write documentation that developers can easily follow. If they still need to ask questions, the docs aren’t good enough yet
- Standardize on tools across teams so your self-service layer doesn’t need to support ten different workflows for the same task
Don’t build self-service for edge cases. Focus on the tasks developers do every week, not the ones they do twice a year. You can handle the rare requests manually for now.
How to know you’re ready for Stage 4: You’re ready for Stage 4 when developers provision common resources on their own, and most teams use golden paths for standard work. Your platform team builds new capabilities, and they don’t waste time answering requests all day. Support tickets are down, and developer velocity is up.
PRO TIP 💡: As you build self-service, you need to know if developers truly use it. Jellyfish DevEx captures developer sentiment alongside productivity metrics, so you can also see whether your new capabilities reduce friction or only create new frustrations.
Stage 3 to 4: Integrate and Govern
Automation and self-service exist, but in silos. At this stage, you tie everything together into a unified platform and add governance that enforces standards automatically.
Focus on these first:
- Give developers a single portal that brings all your tools together. They shouldn’t need to remember which dashboard does what
- Insert policy enforcement into workflows. Security rules, cost controls, and compliance checks should run automatically, not depend on manual reviews
- Connect observability tools so developers can troubleshoot with real-time data without leaving the platform or opening three different tabs
- Track what teams build and how they use the platform. You need this data to spot problems and prove enhancements
Just don’t try to integrate every tool at once. Start with what developers use daily and then expand over time. A platform that does three things well beats one that does ten things poorly.
How to know you’re ready for Stage 5: Developers work through a unified platform for most tasks while governance runs in the background without constant escalations. When your platform feels like infrastructure everyone depends on, you’re ready to optimize.
Stage 4 to 5: Optimize and Evolve
Integration and governance are in place. The platform runs well, and developers trust it. At this stage, you focus on intelligence. The platform learns from usage, helps teams benefit from each other’s work, and measures success through business outcomes.
Here are some of the main priorities at this stage:
- Use platform data to find slow spots and optimize workflows automatically. The system should point out bottlenecks before someone reports them
- Create ways for knowledge to travel between teams. When one team solves a problem, others should find that solution through the platform, not through Slack
- Tie platform metrics to business outcomes like time-to-market, feature velocity, and customer impact
- Run experiments on the platform itself. Test workflow changes, measure what happens, and keep what makes developers faster
Avoid metrics that sound impressive but don’t move the needle. Faster deployments are meaningless if features stall or customers see no benefit.
And don’t treat Stage 5 as a finish line. Tech changes, your org grows, and what worked last year might not work next year. Even a mature platform needs ongoing investment to stay useful.
Jellyfish's Role in Proving Your Platform's ROI
Jellyfish’s Role in Proving Your Platform’s ROI
You can build the most sophisticated platform in your industry, but if you can’t measure its impact, stakeholders will always question the investment.
Platform engineering gets buy-in when you can show continuous improvements in delivery speed, developer satisfaction, and business outcomes.
Jellyfish helps you make that case. It’s an engineering management platform that pulls data from the tools your teams already use and ties it to business outcomes. Plug in Jira, GitHub, GitLab, and your CI/CD systems, and you get a clear picture of where engineering time goes and what value it creates.
Here are just some of the things Jellyfish brings to the table:
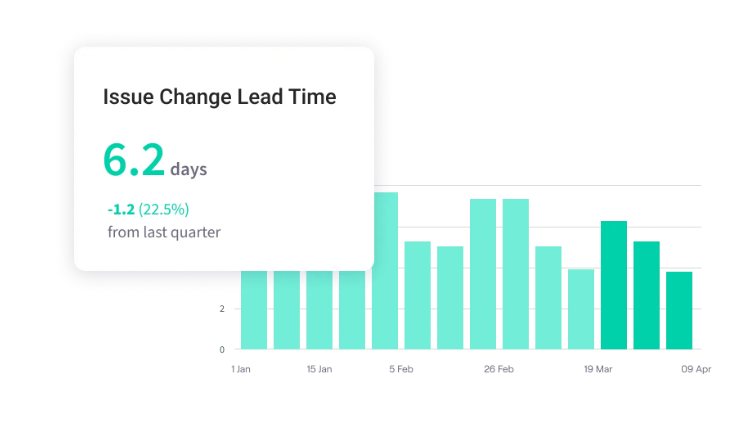
- Measure DORA metrics without manual work: Jellyfish tracks DORA metrics like deployment frequency, lead time, change failure rate, and mean time to restore automatically. You get hard evidence on whether your platform investments make delivery faster and more reliable.
- Stay on top of developer experience data: Jellyfish DevEx runs research-backed surveys that measure developer sentiment alongside system metrics. You can correlate how developers feel about your platform with the productivity numbers it produces.
- Spot bottlenecks in your workflows: Life Cycle Explorer maps where work gets stuck across your software development process. You can prioritize platform improvements that handle the biggest friction points.
- Tie engineering work to financial results: DevFinOps automates R&D cost reporting and gives leadership insights into what engineering investments deliver. You make the case for platform engineering in terms that finance teams care about.
- Benchmark against industry peers: The platform lets you compare your metrics against similar organizations. You can show leadership where you stand relative to competitors and what improvements are realistic to target.
- Measure ROI on AI tools: Jellyfish monitors the adoption and impact of AI tools like GitHub Copilot across different teams and roles. You answer the “is this worth it” question with hard data.
Jellyfish gives you the numbers to prove your platform works. Faster developers, more reliable delivery, and clear value to the business.
Book a demo to see how it can help you measure and communicate your platform’s impact.
FAQs
FAQs
What’s the difference between platform maturity and DevOps maturity?
DevOps maturity measures how well your teams adopt practices like CI/CD, automation, and collaboration between dev and ops.
On the other hand, platform maturity measures how far you’ve built a self-service internal platform that supports those platform engineering practices at scale.
You can have strong DevOps without a mature platform, but a mature platform makes DevOps easier to sustain across the organization.
How long does it take to move from one stage to the next?
Plan for 6-12 months per stage. Smaller companies can compress that timeline, while larger orgs with legacy infrastructure should expect it to stretch.
Trying to jump multiple stages at once usually backfires because you skip foundational work that matters later.
Does my company need to reach the “Optimization” stage to be successful?
No. The maturity model isn’t a race to the top. Stage 5 makes sense for large enterprises with hundreds of engineers and complex needs. For many organizations, Stage 3 or 4 brings everything they need.
The point is to match your platform maturity to your actual needs, not to chase the highest stage for the sake of it.
What is the role of a developer portal (like Backstage) in this model?
A developer portal becomes relevant around Stage 3 and necessary by Stage 4. Tools like Backstage give developers a single interface to access services, documentation, and self-service capabilities.
The portal isn’t the platform itself, but it’s how developers interact with everything you’ve built.
How do DORA metrics relate to the platform maturity stages?
DORA metrics tend to mirror your platform maturity. Early stages show slow, inconsistent performance across teams. But as you build automation and self-service, metrics like deployment frequency and change failure rate improve and become more consistent.
Learn More About Platform Engineering
Learn More About Platform Engineering
- The Complete Guide to Platform Engineering
- Platform as a Product: The Foundation for Successful Platform Engineering
- When to Adopt Platform Engineering: 8 Signs Your Team is Ready
- Platform Engineering vs. DevOps: What’s the Difference?
- How to Build a Platform Engineering Team: Key Roles, Structure, and Strategy
- How to Build Golden Paths Your Developers Will Actually Use
- Best 14 Platform Engineering Tools Heading Into 2026
- 8 Benefits of Platform Engineering for Software Development Teams
- 17 Platform Engineering Metrics to Measure Success and ROI
- 9 Platform Engineering Anti-Patterns That Kill Adoption
- The Top Platform Engineering Skills Every Engineering Leader Must Master
- 11 Platform Engineering Best Practices for Building a Scalable IDP
- What is an Internal Developer Platform (IDP)?
About the author

Lauren is Senior Product Marketing Director at Jellyfish where she works closely with the product team to bring software engineering intelligence solutions to market. Prior to Jellyfish, Lauren served as Director of Product Marketing at Pluralsight.