In this article
DevOps changed how we build software. It broke down walls between development and operations, gave teams more ownership, and made shipping faster. For smaller teams, it worked beautifully.
But as companies scaled past 50, 100, 200 engineers, something changed.
Startups: “You build it, you run it”
Scaleups: “You build it, you configure Kubernetes, you manage CI/CD pipelines, you debug infrastructure, you handle compliance, and somewhere in there, you run it.”
The cognitive load became crushing.
Platform engineering showed up as a potential solution, and immediately, people started calling it “DevOps 2.0” or “rebranded DevOps.” For example, here’s what Reddit users have to say:

The skepticism is understandable. Both deal with infrastructure, automation, and how developers ship code. But they approach the problem differently.
DevOps spreads infrastructure responsibility across every team, while platform engineering consolidates that complexity into self-service tools that developers can use without becoming infrastructure experts.
In this guide, we break down exactly what platform engineering involves, when it makes sense for your team, and how to implement it without creating another bottleneck.
Part 1: Foundations & Core Concepts
Part 1: Foundations & Core Concepts
Platform engineering sounds abstract until you break it down. Before you write code or choose tools, you need to understand what platforms handle, how they should work, and why the product mindset matters more than technical skills.
What is an Internal Developer Platform (IDP)?
An internal developer platform (IDP) is a self-service layer that sits between developers and the infrastructure they need to build and ship software.
It provides standardized tools, workflows, and automation so developers can provision resources, deploy applications, and manage services without waiting on other teams or becoming infrastructure experts themselves.
A solid IDP typically includes several core components:
- CI/CD pipelines that handle builds and deployments automatically
- Infrastructure orchestration that spins up environments on demand
- Observability tools that outline logs, metrics, and traces
- Service catalogs that show what’s running where
- Developer portals that provide a single interface for all platform features
- Configuration management for environment variables and app settings
- Security scanning that’s built into the deployment process
- Cost tracking to monitor resource usage across development teams
The exact mix depends on what your developers need most.
For example, let’s say a developer wants to build a new microservice. Instead of filing tickets, reading Terraform docs, or asking the platform team for help, they open the developer portal, click “New Service,” fill out a few fields (service name, language, database requirements), and hit create.
The platform handles the rest. It provisions infrastructure, sets up CI/CD, configures monitoring, applies security policies, and gives the developer a working service with a deployment pipeline. The whole process takes minutes.
The Guiding Philosophy: Core Platform Engineering Principles
Every successful platform follows a handful of core principles. They’re not complicated, but they’re easy to get wrong. Here’s what you should keep in mind:
- Self-service over tickets: Developers should get what they need without asking permission or waiting on another team. If they have to file a Jira ticket to deploy a service, you haven’t built a platform. Self-service means developers can deploy code and troubleshoot issues through automated workflows, not through human gatekeepers.
- Golden paths, not guardrails: The best platforms make the right way the easy way. Instead of locking developers into rigid templates, you create well-lit paths that guide them toward good practices. Developers can still go off-road when they need to, but 80% of the time, the golden path gets them where they want to go faster than any alternative.
- Products, not projects: Your platform is a product with internal customers. You need to understand what developers need, measure if they use it, and keep improving it. The mistake is treating platforms like projects with an end date. Build it, launch it, forget it.
- Reduce cognitive load: Every choice you force developers to make, every tool they need to learn, every configuration file they need to understand adds to their cognitive burden. The platform’s job is to absorb that complexity. Developers should think about their application logic, not about which AWS region to deploy.
- Enable, don’t gatekeep: Platform teams exist to make developers faster, not to enforce processes for its own sake. Every policy, approval step, or restriction should have a clear reason tied to real risk. Security and compliance matter, but they should happen invisibly through the platform.
These principles shape every decision a platform team makes. They determine which features to build, how to design interfaces, and when to say no to requests that would compromise the platform’s usability.
Platform as a Product: The Strategic Mindset Shift
The biggest mistake platform teams make is treating their work like an internal IT project. They build infrastructure, hand it over, and wonder why developers don’t use it. You need to treat your platform like a product and developers like customers.
This isn’t a metaphor. Developers choose whether to adopt your platform or find alternatives. They have needs, preferences, and pain points. If your platform creates more friction than it removes, they’ll route around it with shadow IT.
Here are some best practices to keep in mind:
- Talk to developers before you build anything: Interview them, track where they get stuck, and look for patterns. If five teams complain about the same deployment bottleneck, that’s your priority, not the fancy service mesh you wanted to implement.
- Measure adoption and satisfaction like any product team would: Track how many teams use the platform, how often they use it, and whether they’d recommend it. If usage stays flat or satisfaction drops, fix what’s broken before you build new features.
- Maintain a public roadmap that developers can see: They should know what’s coming, what you’re working on now, and why. Transparency builds trust and reduces the constant stream of “can you add this?” requests.
- Create support channels and close the feedback loop: Make it easy to report problems and ask for features. Then tell people when you fix their bugs or explain why their feature request didn’t make the cut.
The point is that your platform’s success depends more on whether developers want to use it than on how well you built it. Product thinking is how you figure out what they want.
Part 2: Strategic Context & Comparisons
Part 2: Strategic Context & Comparisons
People love to argue about whether platform engineering is just DevOps with a new name. And sure, the comparison might make sense on the surface, but it misses what makes each approach different.
Platform Engineering vs. DevOps: An Evolution, Not a Replacement
The confusion is fair. Both deal with infrastructure, automation, and developer productivity. One Reddit user explained the skepticism well:
In my personal experience, it’s just a rebrand. I’ve been a SysAdmin, DevOps Engineer, Platform Engineer, and Cloud Engineer. The only difference to me has been the tech stack and how companies do things differently in processes/team layout, etc.
It’s easy to see why people think this way. The tools overlap, and the problems seem similar. But DevOps and platform engineering handle different problems.
DevOps broke down the wall between development and operations. Instead of developers throwing code over the fence and waiting for ops to deploy it, teams owned their entire stack. “You build it, you run it” became the mantra, while DevOps gave developers more control and faster feedback loops.
The approach worked. Teams shipped faster, incidents got resolved quicker, and the old ticket-based deployment process died. DevOps was a genuine improvement over what came before.
Platform engineering takes a different approach. Here’s how one Redditor described it:
Platform Engineering is about streamlining platforms for self-service, primarily concerned with removing or abstracting away points of friction. It’s a support role for development roles more directly concerned with core business functions.
That’s the core differentiator. Platform engineering builds products that abstract infrastructure complexity. Instead of every developer learning Kubernetes, Terraform, and AWS, a specialized platform team builds self-service tools that handle that complexity.
The differences become clearer when you compare how each approach handles core aspects of the work:
| Aspect | DevOps | Platform engineering |
| Responsibility distribution | Spreads infrastructure knowledge across all teams. Every developer needs to understand deployment pipelines and incident response. | Centralizes expertise in a dedicated operations team and packages it as a product that other teams consume. |
| Team structure | Product teams handle their own infrastructure alongside application code. | The platform team builds and maintains infrastructure tooling that product teams use. |
| Developer experience | Gives developers full access to infrastructure tools and expects them to manage complexity. | Hides complexity behind abstractions so developers focus on application logic. |
| Scale point | Works well with 20-50 engineers, where everyone can learn the infrastructure. | Becomes necessary at 100+ engineers where distributing that knowledge creates bottlenecks. |
Platform engineering doesn’t replace DevOps. It scales DevOps principles for larger organizations. The DevOps culture of ownership, automation, and collaboration is still there. But instead of every team reinventing solutions, the platform team builds shared infrastructure that embodies those principles.
Platform Engineering vs. SRE: Different Roles, Shared Goals
Some people also assume platform engineering and site reliability engineering (SRE) are the same thing. They’re not, though they often work closely together.
Site reliability engineering focuses on keeping systems reliable and available. They set service level objectives (SLOs), manage error budgets, respond to incidents, and reduce toil. They’re also on-call for production systems and spend their time making sure services stay up and perform well.
Platform engineering focuses on developer productivity and velocity. The goal is to reduce friction in the development process, not manage production reliability.
This Reddit user gave us a simple way to think about it:

Those differences play out in how each role spends their time:
| Aspect | SRE | Platform engineering |
| Primary focus | System reliability, availability, and performance in production | Developer productivity and autonomous self-service |
| Key metrics | SLOs, error budgets, uptime, latency, and incident response time | Developer satisfaction, time-to-deploy, platform adoption rates |
| Main responsibilities | On-call rotations, incident response, capacity planning, and toil reduction | Build CI/CD pipelines, developer portals, and infrastructure abstractions |
| Who they serve | End users and customers who depend on system availability | Internal application developers who need to ship code efficiently |
| Typical work | Monitor production, respond to alerts, conduct postmortems, optimize performance | Create deployment workflows, build self-service tools, and improve developer experience |
In practice, many companies need both roles. Platform engineers make it easy to deploy services, while SREs make sure those services stay reliable once deployed. The collaboration makes both teams more effective.
Part 3: Strategy & Planning
Part 3: Strategy & Planning
Most platform failures happen in the planning stage. Teams build the wrong things, staff incorrectly, or start before they’re ready.
Getting the strategy right means understanding when you need a platform, what to build first, and who should build it.
When to Adopt Platform Engineering: A Guide for Growing Teams
Not every company needs platform engineering right now.
If you’re too early, you waste time solving problems that don’t exist yet. If you’re too late, your developers burn out on infrastructure work while competitors move faster.
You can use this assessment to evaluate whether your team is ready for platform engineering:
| Factor | Green light 🟢 (ready) | Yellow 🟡 (getting close) | Red light 🔴 (too early) |
| Team size | 100+ engineers across multiple teams | 50-100 engineers, growing fast | Under 50 engineers |
| Deployment friction | Developers wait days for infrastructure, or deployments need multiple team approvals | Deployments take hours, occasional bottlenecks, and some manual steps remain | Deployments happen in minutes with minimal friction |
| Infrastructure complexity | Multi-cloud, microservices, multiple environments, compliance requirements | Growing number of services, some cloud complexity, increasing env management overhead | Simple stack, monolith, or a few services, single cloud provider |
| Developer complaints | Common complaints about infrastructure, teams building duplicate tooling, and requests for better DevEx | Occasional frustration, some teams are more productive than others, growing tool sprawl | Rare complaints, developers focus mostly on product work |
| Shadow IT | Teams actively building workarounds, using unauthorized tools, or avoiding official processes | Some teams are starting to build their own solutions or exploring alternatives | Teams use standard tooling without friction |
| Onboarding time | New developers take weeks to deploy their first service | New developers take several days to get productive | New developers ship code within a day or two |
| Context switching | Developers spend 30%+ of their time on infrastructure, tooling, and DevOps work | Developers split time between product and infrastructure work | Developers spend 80%+ of their time on product features |
Here’s how to interpret your results:
- Mostly green: You need platform engineering now. Infrastructure complexity eats your developers’ time every day. An internal platform team will pay for itself quickly through faster deployments and happier developers.
- Mostly yellow: Start planning. You’re getting close to the point where platform engineering makes sense. Standardize your developer workflows, create some basic self-service platforms, or hire your first platform engineer to explore what you need.
- Mostly red: Wait. Your team isn’t large enough or complex enough to justify the investment. Focus on good DevOps practices, document your processes, and revisit this assessment in six months. Premature platform engineering creates overhead without benefits.
- Mixed results: Think about where you’re headed. If you’re hiring fast and adding infrastructure complexity, start sooner. If growth is steady and your stack is stable, you can wait. The key question is whether your current approach will break in the next 6-12 months.
If you’re unsure, run this assessment every quarter. Platform engineering needs grow gradually, then suddenly. You’ll know when the pain becomes obvious enough to act.
Building Your Platform Engineering Roadmap
The best roadmaps balance quick wins that prove value with foundational work that scales over time. Here’s a template you can use to structure yours.
| Phase | Timeline | Focus | Key initiatives |
| Phase 0: Assessment | 1-2 months | Understand the current state and form a team | Developer interviews, pain point mapping, tool audit, and hire core team members |
| Phase 1: Foundation | 0-6 months | Quick wins and basic self-service | Standardize CI/CD pipelines, create deployment templates, build a basic developer portal, and set up golden paths for common tasks |
| Phase 2: Expansion | 6-12 months | Core platform capabilities | Self-service environment provisioning, integrated observability, service catalog, and infrastructure as code workflows |
| Phase 3: Maturity | 12-24 months | Advanced features and optimization | Advanced security scanning, cost optimization tools, multi-cloud support, developer productivity analytics, and platform API |
Make sure to build buffers into your timelines. Unexpected issues will come up. Developers might need support, or a production incident could pull your attention.
Plan for 60-70% of your time going to roadmap work and the rest going to maintenance, support, and firefighting.
It’s also a good idea to create feedback channels so developers can influence the roadmap. Office hours, surveys, and Slack channels all work. The roadmap shouldn’t be set in stone. It should evolve based on what developers need and what’s working.
PRO TIP 💡: Use Jellyfish to understand current resource allocation before you build your roadmap. See how much time developers spend on infrastructure work versus product features today. This baseline helps you prioritize which platform capabilities will have the biggest impact.
How to Structure a Platform Engineering Team (and the Skills You’ll Need)
There’s no single way to structure a platform team. Most companies pick one of these approaches, and each one comes with different trade-offs:
- Centralized platform team: A specialized team builds and maintains the platform for everyone. Product teams use what the platform team creates, but don’t contribute to it. This works well once you hit 100+ engineers and need specialization. The downside is that the platform team can lose touch with what developers need day-to-day.
- Embedded platform engineers: Platform engineers sit within product teams and contribute to both product work and platform improvements. This keeps the work close to real problems, but creates inconsistency across teams since everyone builds differently. Works best for smaller companies with 50-100 engineers who haven’t standardized continuous delivery yet.
- Hybrid model: A central platform team builds core infrastructure while embedded engineers help product teams use it and report back what’s missing. You get centralized expertise plus on-the-ground context. Most mature platform teams use this approach, though it needs more coordination to work well.
Start small. Your first platform hire should be a generalist who can code, understand the underlying infrastructure, and talk to developers. For 2-3 people, you need engineers who can ship working tools fast.
For 5-8 people, add a product manager to handle prioritization and stakeholder communication. More than 10 people, and you can specialize into sub-teams focused on CI/CD, infrastructure, developer experience, or security.
Keep in mind that the right structure only works if you have the right skills on the team. Platform engineers need to balance technical depth with product thinking and communication abilities:
| Skill Category | Why It Matters | Examples |
| Infrastructure & automation | Core technical work of building the platform | Terraform, Kubernetes, cloud platforms (AWS/GCP/Azure), CI/CD systems |
| Software engineering | Platforms are products that need quality code | API design, testing, observability, performance optimization |
| Product thinking | Understanding user needs and prioritization | User research, roadmap planning, metrics definition, saying no |
| Communication | Adoption depends on how well you explain things | Documentation, presentations, developer support, stakeholder management |
The biggest mistake is hiring pure infrastructure people with no product sense. Technical skills matter, but understanding developers as customers matters more.
Part 4: Core Practices & Execution
Part 4: Core Practices & Execution
You can plan perfectly and still build something developers hate. Execution comes down to a handful of practices that either remove friction or create it, and knowing which anti-patterns will sabotage you before they do.
Defining Golden Paths: Paving the Way for Developer Productivity
Golden paths are opinionated, well-supported workflows for common tasks. They’re the standardized way to deploy a service, provision a database, or set up monitoring.
Instead of forcing developers into rigid templates, you create a path that handles 80% of use cases beautifully. Developers who follow the golden path get automation, best practices, and support built in.
Those who need something different can still go off-road, but most of the time, the golden path is faster and easier than any alternative.
What makes a good golden path:
- Well-documented: Developers should understand what the path does and how to use it without asking anyone. Clear examples, troubleshooting guides, and explanations of the underlying concepts all help.
- Actively maintained: Golden paths rot quickly if nobody updates them. As tools change and best practices evolve, the paths need to keep up. Neglected golden paths slowly become obstacles.
- Covers the common cases: A golden path that only works for 30% of use cases isn’t golden. It should handle the majority of scenarios developers encounter. If teams constantly need exceptions, you’ve built the wrong path.
- Includes escape hatches: The other 20% of use cases need a way out. Developers should be able to customize, override, or skip parts of the golden path when they have legitimate reasons.
- Built on best practices: Security scanning, proper configuration management, and other good habits should come automatically. Developers get these benefits without thinking about them.
When you update a golden path, communicate the changes clearly. If you dismiss an old approach, give teams time to migrate and provide migration guides. A golden path that breaks existing services stops being golden.
PRO TIP 💡: Use Jellyfish to track which developers follow your golden paths versus those who go off-road. Compare productivity metrics like deployment frequency and lead time between the two groups to see if your golden paths actually reduce friction or just add process.

Platform Engineering Best Practices to Follow
Platform engineering involves dozens of decisions about what to build, how to build it, and how to run it. Here are the practices that matter most:
- Treat documentation as a first-class feature: Developers won’t use what they don’t understand. Every platform capability needs clear docs that explain what it does, how to use it, and how to troubleshoot common issues.
- Build feedback loops into everything: Office hours, surveys, usage analytics, and support channels all help you understand what works and what doesn’t. Close the loop by telling developers what you heard and what you’re doing about it.
- Design for day-two operations, not just day one. Deploying a service is easy. Maintaining it for two years is hard. Your platform should handle upgrades, scaling, backups, disaster recovery, and security patches automatically. If developers have to think about these things, your platform hasn’t abstracted enough.
- Automate toil aggressively. Any manual process that happens more than once a week should be automated. Ticket-based workflows, manual approvals, and repetitive configuration all slow teams down.
- Set standards, but allow exceptions. Golden paths should guide 80% of the work. The other 20% needs escape hatches. When teams request exceptions, understand why before saying yes or no.
- Version and deprecate thoughtfully. Your platform will evolve, and some features will need to sunset. Version your APIs and tools clearly. When you deprecate something, give teams at least two quarters to migrate and provide automated migration paths when possible.
Common Platform Engineering Anti-Patterns to Avoid
Platform teams make similar mistakes regardless of company size or industry. Catch these anti-patterns early and you’ll save yourself months of rebuilding and damaged credibility:
- Building in isolation without user input: You spend months creating what you think developers need, launch it with fanfare, and watch adoption flatline. Developers ignore it because it doesn’t solve their actual problems or fit their workloads. Always validate your assumptions with real users.
- Becoming a ticket queue instead of a product team: Every request becomes a ticket, and your team turns into order-takers who fulfill them without any strategy. Platform teams need product discipline to avoid becoming glorified ops teams with better tooling.
- Forcing adoption through mandates: Leadership declares that everyone must use the platform, but developers hate it and find creative workarounds. Forced adoption only creates resentment and shadow IT. Build something developers want to use, and the adoption will take care of itself.
- Over-engineering for theoretical future needs: You build complex, flexible systems for scenarios that might never happen, while developers suffer with today’s problems. Perfect architecture matters less than solving current pain points quickly.
- Neglecting documentation and developer experience: The platform works great if you understand the architecture, but developers can’t figure out how to use it. Onboarding takes weeks, error messages are cryptic, and nobody maintains the docs. Technical excellence means nothing if developers can’t access it easily.
- Letting the platform stagnate: You launch features and move on without maintenance, updates, or improvements. Six months later, the platform uses outdated tools, doesn’t reflect current best practices, and developers complain it’s falling apart.
Part 5: Value, Measurement & Examples
Part 5: Value, Measurement & Examples
Leadership wants to know if platform engineering is worth the cost. The answer depends on tracking the right metrics, understanding what success looks like, and learning from companies that have already proven the model works.
The Business Benefits of Platform Engineering
When done right, platform engineering pays dividends across the entire engineering organization. Here’s what organizations typically see:
- Accelerated software delivery cycles: Among organizations that have mature platform engineering practices, 71% report they’ve significantly sped up their time to market. Automation and self-service capabilities compress what used to take days or weeks into minutes, which means features reach production much faster.
- Decreased technical debt burden: Developers spend 42% of their working week dealing with technical debt, which costs nearly $85 billion worldwide in opportunity costs annually. Platform engineering solves this by embedding quality standards into automated workflows, so bad code gets caught before it reaches production.
- Consolidated toolchains reduce friction: Developers waste 6 to 15 hours each week just switching between different tools. Platform engineering solves this by building a single place where developers can deploy code, check logs, and find documentation without opening yet another app.
- Improved security and compliance posture: 49% of organizations adopt platform engineering specifically to strengthen security and compliance. Platforms build security policies directly into deployment pipelines, so every release gets scanned and validated automatically without manual reviews.
- Reduced context switching and cognitive load: Context switching costs developers an average of 23 minutes and 15 seconds to return to their original task. Platform engineering protects this focus by automating routine infrastructure work and making deployments self-service.
How to Measure Success: Key Platform Engineering Metrics
Platform engineering metrics show whether the platform speeds up the software development lifecycle, where problems exist, and whether continued investment makes sense. Ideally, you should pay attention to both technical performance and user adoption.
Technical and productivity metrics show whether your platform helps teams ship faster and more reliably. They’re based on the DORA metrics that correlate with high-performing engineering organizations.
| Metric | What it measures | Why it matters | Good target |
| Deployment frequency | How often teams deploy to production | Higher frequency means less friction in the deployment process. | Multiple times per day (elite), daily to weekly (high performing) |
| Lead time for changes | Time from code commit to running in production | Shorter lead times mean faster feedback and iteration. Good platforms cut this down through automation and self-service. | Less than one day (elite), one day to one week (high performing) |
| Time to restore service | How quickly teams recover from incidents | Platforms with good observability and automated rollback push this number down. | Less than one hour (elite), less than one day (high performing) |
| Change failure rate | Percentage of deployments that cause problems and need fixes | Lower rates show your platform provides good testing, gradual rollouts, and safety checks. | 0-15% (elite/high performing) |
| Time to first deployment | How long new developers or services take to ship code to production | This proves platform usability directly. Fast onboarding proves you removed friction. | Within one day (good), within hours (excellent) |
User-centric and adoption metrics show the other side of platform success. They track whether developers use what you build and whether they’re happy with it.
| Metric | What it measures | Why it matters | Good target |
| Platform adoption rate | Percentage of teams or services that use the platform | Low adoption means the platform doesn’t solve real problems. Track both overall and feature-specific adoption. | 80%+ of teams for mature platforms |
| Developer satisfaction | Survey scores that rate platform experience | Shows whether developers find the platform valuable. Track trends over time and get qualitative feedback. | NPS above 30, satisfaction score above 4/5 |
| Self-service completion rate | Percentage of tasks developers complete without help | High rates prove your abstractions work. Low rates point to complexity or poor documentation. | 90%+ for common tasks |
| Support ticket volume | Number and type of support requests | Should drop as the platform matures. Ticket categories reveal what needs better docs or simpler interfaces. | Drops over time, concentrated on complex edge cases |
| Feature adoption by the team | Which teams use which features | Reveals struggles with specific features or teams. Uneven patterns help you target improvements. | Evenly spread across teams |
Track these metrics in a dashboard that your whole team can see. The numbers will tell you what’s working, what needs attention, and whether your roadmap priorities make sense. Remember to use them to guide decisions, not to chase perfect scores.
Real-World Platform Engineering Examples in Action
The best way to understand platform engineering is to see how companies put it into practice. Here’s how three tech companies built platforms that made their developers faster and more productive.
Netflix – One Platform Console for Dozens of Developer Tools
Challenge: Netflix adopted microservices early, but developers soon worked with dozens of fragmented tools across the SDLC. They moved between Bitbucket for code reviews, Spinnaker for deployments, Jenkins for builds, and various monitoring tools. The constant switching slowed them down and created errors. Teams relied on tribal knowledge to figure out which tools to use.
What they built: Netflix’s Platform Experiences and Design team built a federated platform console that acts as a single entry point. It consolidates dozens of tools in one interface, backed by GraphQL Federation.
They used Backstage (Spotify’s open-source framework) for the frontend and connected it to their GraphQL API, Domain Graph Services, and Hawkins design system.
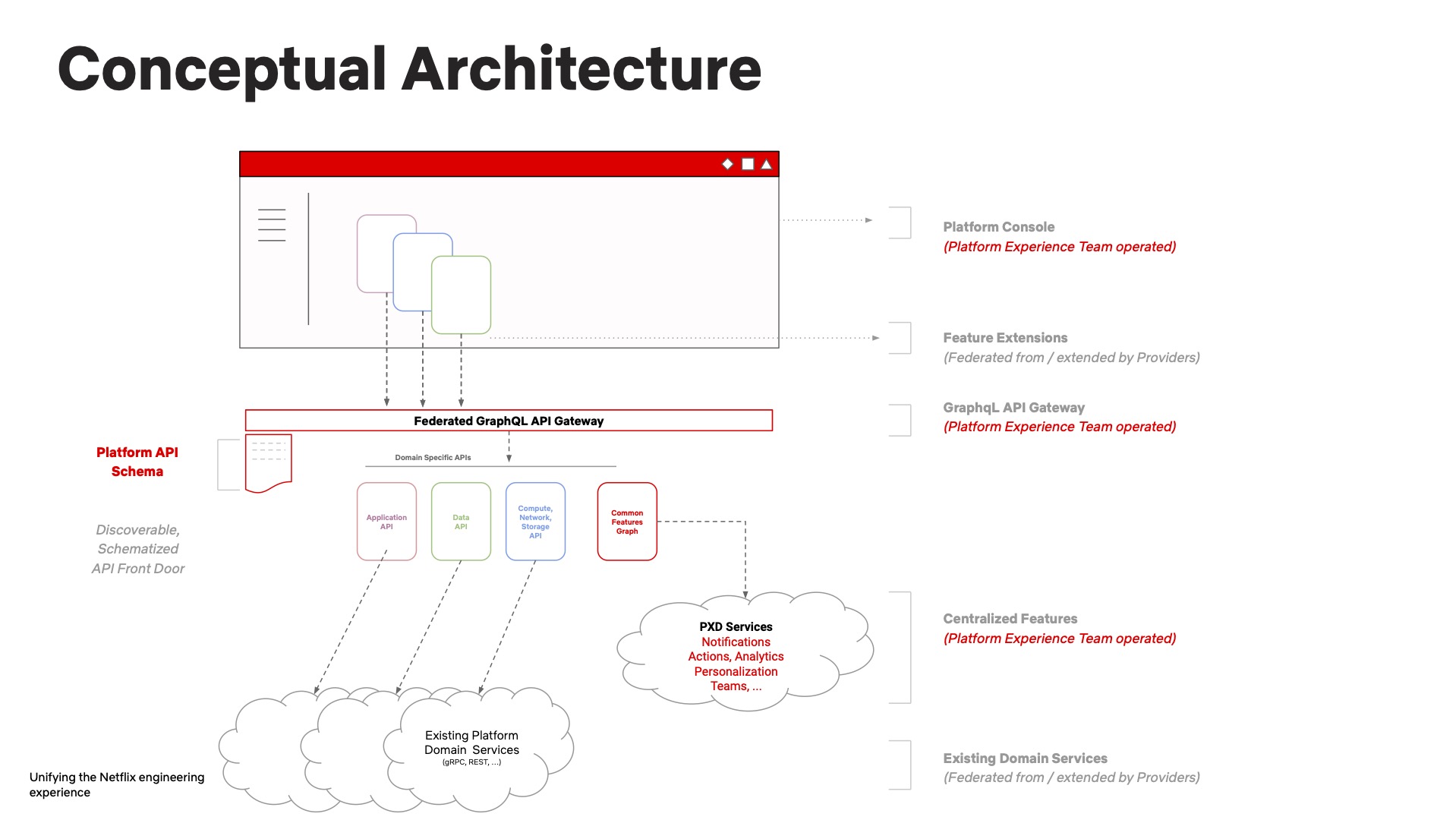
(Source: Platform Engineering)
The diagram shows how Netflix’s federated architecture works. A GraphQL API Gateway routes requests to Domain Graph Services.
Each service handles a specific portion of the schema. Teams can own their services independently while developers get a consistent experience.
Results: A single front door for all platform tools should reduce the inefficiencies from constant context switching. Developers can find what they need faster without asking around or relying on institutional knowledge. The single interface likely frees up time that was previously spent jumping between platforms.
Spotify – Open-Source Developer Portal That Started It All
Challenge: Around 2016, Spotify went through a hiring boom during explosive growth, but productivity didn’t improve despite all the new hires. Engineers spent hours each week searching for documentation, platforms, systems, and their owners across a scattered system. Each squad had its own setup with no centralized docs or standards. Developers had to learn the same things over and over because teams implemented everything differently.
What they built: Spotify developed Backstage to help engineers find, manage, and create everything in one place. The platform works as a software catalog, developer portal, and documentation hub.
Backstage nudges teams toward “Golden Paths” (best practices and standards), without forcing compliance. This preserved Spotify’s autonomous culture. In 2020, Spotify open-sourced it and donated it to the CNCF.
Results: Onboarding time dropped from over 60 days to just 20 days after Backstage launched. Today, 280 engineering teams at Spotify use it to manage 2,000+ backend services, 300 websites, 4,000 data pipelines, and 200 mobile features.
An internal study found that frequent Backstage users are 2.3x more active in GitHub, create 2x as many code changes in 17% less cycle time, deploy software 2x as often, and keep their software deployed 3x longer. (Source: Spotify)
Uber – DevPod Remote Development Environment
Challenge: Each week, Uber’s 4,500 stateless microservices were deployed more than 100,000 times by 4,000 engineers and autonomous systems. Hundreds of independent teams developed, deployed, and operated these services globally. Service management and placement stayed highly manual — engineers had to decide which zone (physical data center) to run services in. (Source: Uber)
What they built: In 2018, Uber’s platform team started working on Up, a multi-cloud control plane that automates service placements and infrastructure migrations. Up consolidated deployments, capacity management, compliance, and daily operations into one platform. Services can run in any zone and move automatically between data centers without human involvement.
Results: Uber spent two years making microservices portable and migrated them to Up with mostly automated processes. The change brought major cost savings from autoscaling and cut the maintenance load on teams. Most microservices now run on Up, which lets Uber move to the cloud without disrupting service teams. Rollout policy changes that used to take months now happen centrally.
Part 6: Platform Engineering Tools
Part 6: Platform Engineering Tools
Platform engineering tools range from open-source frameworks to all-in-one commercial products.
This section breaks down the categories that matter and the solutions worth considering when you’re ready to build or buy.
A Leader’s Guide to the Platform Engineering Tools
Your platform needs tools, but tools alone don’t make a platform. A platform is the layer that integrates these tools into simple workflows that developers can use without thinking about the infrastructure underneath.
Here’s a breakdown of the tool categories that make up a modern internal developer platform.
| Tool category | What it does | When you need it |
| CI/CD and deployment | Automates builds, tests, and deployments from code commit to production | From day one. Every platform needs automated deployment pipelines. |
| Infrastructure as code (IaC) | Manages infrastructure through code instead of manual configuration | Early. Important for consistency across environments. |
| Container orchestration | Manages containerized applications at scale, handles scheduling and scaling | When you have multiple services and need automated scaling and management. |
| Observability | Provides monitoring, logging, and tracing to understand system behavior | Early. Developers need visibility into their services from the start. |
| Developer portals | Centralizes platform access with service catalogs, docs, and self-service workflows | Mid-stage. Once you have multiple tools and need a unified interface. |
| Service mesh | Manages service-to-service communication, security, and observability in microservices | Later stage. Only needed with many microservices that require complex networking. |
| Cost management | Tracks and optimizes cloud spending across teams and services | Mid-stage. Important once cloud bills become significant. |
| Security scanning | Identifies vulnerabilities in code, containers, and infrastructure | Early. Build security into deployment pipelines from the start. |
Just remember that no single tool makes a platform. Start simple, integrate well, and add new tools only when the problem becomes obvious.
Best Platform Engineering Solutions
Not every organization needs to build a platform from scratch. Pre-built solutions can get you to a working platform faster, especially if you have a small team or limited platform engineering expertise.
Some products try to handle the entire platform engineering problem in one integrated package. These all-in-one solutions cover multiple aspects of the platform and are built to get you running quickly:
- Humanitec: Handles application configuration and environment provisioning through a developer-friendly interface that abstracts Kubernetes and cloud-native complexity. Works well for teams that want pre-configured workflows without building everything from scratch.
- Kratix: An open-source framework that gives you structure for building platforms on Kubernetes. You get proven patterns, but need to invest time in setup and customization. Best for teams that want architectural access control.
- mia-platform: Covers design through deployment with built-in templates, API management, and microservices orchestration. Good for organizations that want comprehensive tooling in one package instead of assembling pieces.
There are also developer portal platforms that provide the front door to your platform, where developers can find services, access documentation, and trigger workflows:
- Backstage: The open-source platform from Spotify, now a CNCF project. It provides service catalogs, documentation, and a plugin architecture for customization. Strong extensibility makes it powerful, but you need engineering resources to set it up and maintain it properly.
- Port: A commercial developer portal with built-in workflows, service catalogs, and scorecards. It needs less setup than Backstage and ships with more features out of the box, working well for teams that want a portal quickly without heavy customization.
- Cortex: Focuses on service maturity, scorecards, and operational readiness alongside standard catalog functionality. It helps platform teams track adoption and service quality.
If you want to build platform capabilities on top of your existing infrastructure, framework-style tools give you the foundation without dictating everything:
- Crossplane: Extends Kubernetes to manage cloud infrastructure. You define infrastructure as Kubernetes resources and build composable APIs on top. Best for teams already deep in Kubernetes who want to abstract infrastructure the same way they abstract applications.
- Upbound: Commercial version of Crossplane with extra management features and support. Takes the operational burden out of running Crossplane at scale while using the same core approach.
Your constraints guide the choice. Small teams with limited platform experience need all-in-one solutions. Teams with strong engineers benefit from customizable frameworks like Backstage or Kratix. Kubernetes-heavy organizations should start with Crossplane.
Most companies use a hybrid approach. They might run Backstage as their developer portal but build custom capabilities around it, or use Humanitec for environments while keeping their existing CI/CD.
Measuring Your Platform's Success with Jellyfish
Measuring Your Platform’s Success with Jellyfish
Most platform teams know their work makes a difference, but struggle to show it clearly. Deployment data sits in CI/CD tools, adoption metrics in analytics, and developer feedback comes through surveys.
Platform teams have to piece together their own dashboards or reports to connect those dots. But with Jellyfish, that’s not the case anymore.
Jellyfish is a software engineering intelligence platform that integrates with your Git repos, project management tools, and deployment systems to track how engineering work flows through your organization.
Platform engineering teams can use it to:
- Measure platform adoption across teams: Track which teams use your platform and which features they adopt. Jellyfish shows you adoption rates over time so you can identify what works and where developers need better onboarding or documentation.
- Prove productivity improvements with DORA metrics: Compare deployment frequency, lead time, and change failure rates before and after platform adoption. Jellyfish benchmarks your performance against industry standards so you can show leadership concrete productivity gains.
- Understand resource allocation and reduce toil: See how much time developers spend on roadmap work versus infrastructure management, support tickets, and unplanned tasks. Platform teams use this data to identify where self-service tools cut the most friction and where more automation is needed.
- Track AI coding tool impact on your platform: Monitor how AI tools like GitHub Copilot, Cursor, and others affect developer productivity within your platform workflows. Jellyfish compares adoption and impact across different tools so you can optimize your AI strategy alongside platform improvements.
- Collect developer feedback with DevEx surveys: Deploy targeted surveys that ask developers about their experience with your platform. The feedback connects directly to performance data, so you can see which complaints correlate with actual productivity issues.
- Automate software capitalization reporting: Create software capitalization reports automatically based on actual engineering activity. Finance gets precise, auditable data about development work without asking engineers to fill out timesheets or estimate hours.
Your platform might be excellent, but excellent needs receipts. Jellyfish bridges the gap with data on adoption, deployment velocity, and where developer time goes. You get the numbers to show executives what changed.
Schedule a demo and see what Jellyfish can do for your platform.
Learn More About Platform Engineering
Learn More About Platform Engineering
- Platform as a Product: The Foundation for Successful Platform Engineering
- When to Adopt Platform Engineering: 8 Signs Your Team is Ready
- Platform Engineering vs. DevOps: What’s the Difference?
- How to Build a Platform Engineering Team: Key Roles, Structure, and Strategy
- Understanding The Platform Engineering Maturity Model
- How to Build Golden Paths Your Developers Will Actually Use
- Best 14 Platform Engineering Tools Heading Into 2026
- 8 Benefits of Platform Engineering for Software Development Teams
- 17 Platform Engineering Metrics to Measure Success and ROI
- 9 Platform Engineering Anti-Patterns That Kill Adoption
- The Top Platform Engineering Skills Every Engineering Leader Must Master
- 11 Platform Engineering Best Practices for Building a Scalable IDP
- What is an Internal Developer Platform (IDP)?
About the author

Lauren is Senior Product Marketing Director at Jellyfish where she works closely with the product team to bring software engineering intelligence solutions to market. Prior to Jellyfish, Lauren served as Director of Product Marketing at Pluralsight.